> ## Documentation Index
> Fetch the complete documentation index at: https://www.integrate.io/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# ETL: Xplenty로 XML 데이터 처리
> Integrate.io ETL에서 XmlExtract 등 전용 함수를 활용해 XML 형식의 파일 데이터를 손쉽게 파싱하고, CSV나 JSON과 같은 방식으로 데이터 파이프라인 안에서 처리하는 방법을 예제로 설명합니다. 화면 캡처와 함께 단계별로 정리했습니다.
Xplenty를 사용하면 CSV 파일 외에도 JSON 및 XML 데이터 형식을 쉽게 처리할 수 있습니다.
이 가이드에서는 Xplenty에서 XML을 쉽게 처리할 수 있는 기능을 예로 들어 보겠습니다.
**개요 및 리소스**
데모를 위해 처리할 샘플 XML 파일에 대한 [링크](https://learn.microsoft.com/en-us/previous-versions/windows/desktop/ms762271\(v=vs.85\))는 여기 입니다.
파일은 다음 이미지와 같은 XML 구조로 되어 있습니다.
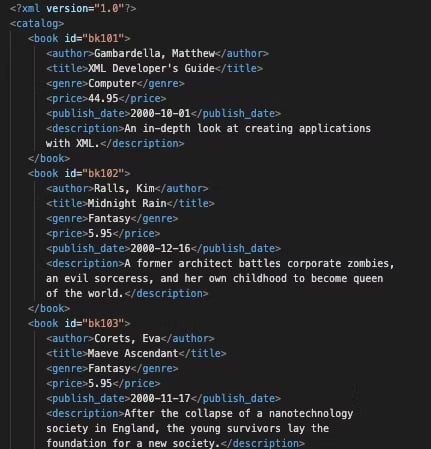 이 데이터를 처리하기 위해 반드시 알아 두어야 할 것은 Xplenty의 함수 [XPath](https://www.integrate.io/docs/etl/xpath/) 와 [XPathToBag](https://www.integrate.io/docs/xpathtobag/) 입니다. 이 두 함수를 데이터 파이프라인에서 검증해 봅시다.
**Xplenty 데이터 파이프라인 구성**
이 데이터를 처리하기 위해 반드시 알아 두어야 할 것은 Xplenty의 함수 [XPath](https://www.integrate.io/docs/etl/xpath/) 와 [XPathToBag](https://www.integrate.io/docs/xpathtobag/) 입니다. 이 두 함수를 데이터 파이프라인에서 검증해 봅시다.
**Xplenty 데이터 파이프라인 구성**
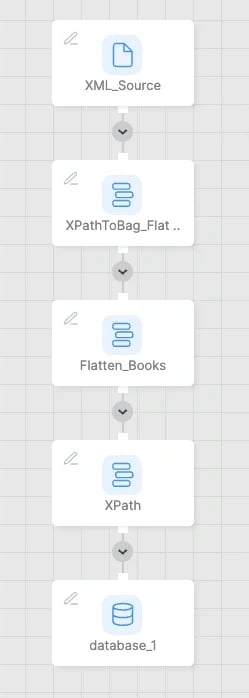 Xplenty 파이프라인의 구성 요소를 각각 차례로 설명합니다.
*
**XML\_Source** : 위에서 공유한 링크의 XML 파일을 클라우드 스토리지에 복사하고 File Storage Source 컴퍼넌트를 사용하여 읽어 들입니다.
*
**XPathToBag** : 이 단계에서는 XPath `/catalog/book`와 일치하도록 XPathToBag 함수를 호출합니다. 이것은 Bag 데이터 유형 `<catalog> </catalog>`아래의 모든 책을 검색합니다.
예)`XPathToBag(data,'/catalog/book')`
*
**Flatten\_Books** : Flatten() 함수를 사용하여 구조체의 각 레코드를 별도의 book 레코드로 가져옵니다.
Xplenty 파이프라인의 구성 요소를 각각 차례로 설명합니다.
*
**XML\_Source** : 위에서 공유한 링크의 XML 파일을 클라우드 스토리지에 복사하고 File Storage Source 컴퍼넌트를 사용하여 읽어 들입니다.
*
**XPathToBag** : 이 단계에서는 XPath `/catalog/book`와 일치하도록 XPathToBag 함수를 호출합니다. 이것은 Bag 데이터 유형 `<catalog> </catalog>`아래의 모든 책을 검색합니다.
예)`XPathToBag(data,'/catalog/book')`
*
**Flatten\_Books** : Flatten() 함수를 사용하여 구조체의 각 레코드를 별도의 book 레코드로 가져옵니다.
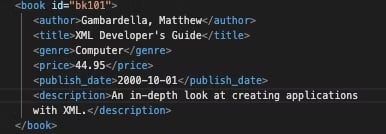 ※ XPathToBag와 Flatten\_Books를 하나로 묶어 `Flatten(XPathToBag(data,'/catalog/book'))`로 축약도 가능합니다.
*
**XPath** : 이 단계에서는 XPath 함수를 사용하여 book 구조체의 개별 요소를 검색할 수 있습니다. 여기서는 위의 `<book> </book>`구조체에 XPath를 설정한 컴포넌트를 살펴보자.
※ XPathToBag와 Flatten\_Books를 하나로 묶어 `Flatten(XPathToBag(data,'/catalog/book'))`로 축약도 가능합니다.
*
**XPath** : 이 단계에서는 XPath 함수를 사용하여 book 구조체의 개별 요소를 검색할 수 있습니다. 여기서는 위의 `<book> </book>`구조체에 XPath를 설정한 컴포넌트를 살펴보자.
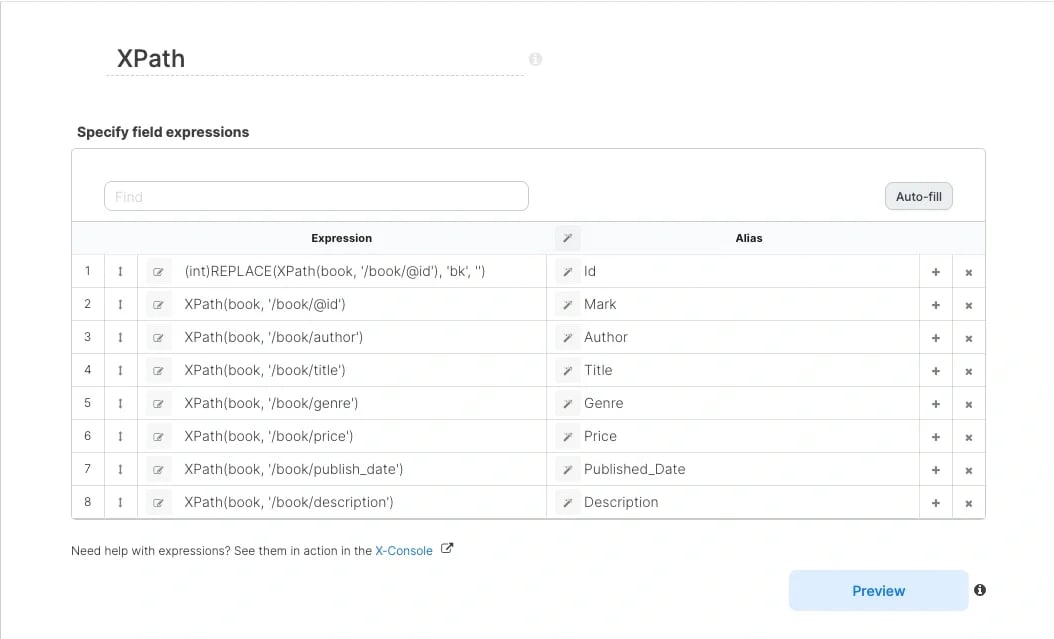 XPath와 그 예에 대한 추가 참조는 [freeformatter.com](https://www.freeformatter.com/xpath-tester.html) 과 같은 XPath 평가 도구를 참조하십시오.
*
**Destination** : XML에서 처리된 개별 필드는 Destination(이 예에서는 BigQuery 테이블)에 저장됩니다.
다음 이미지는 출력된 레코드의 예를 보여줍니다.
XPath와 그 예에 대한 추가 참조는 [freeformatter.com](https://www.freeformatter.com/xpath-tester.html) 과 같은 XPath 평가 도구를 참조하십시오.
*
**Destination** : XML에서 처리된 개별 필드는 Destination(이 예에서는 BigQuery 테이블)에 저장됩니다.
다음 이미지는 출력된 레코드의 예를 보여줍니다.
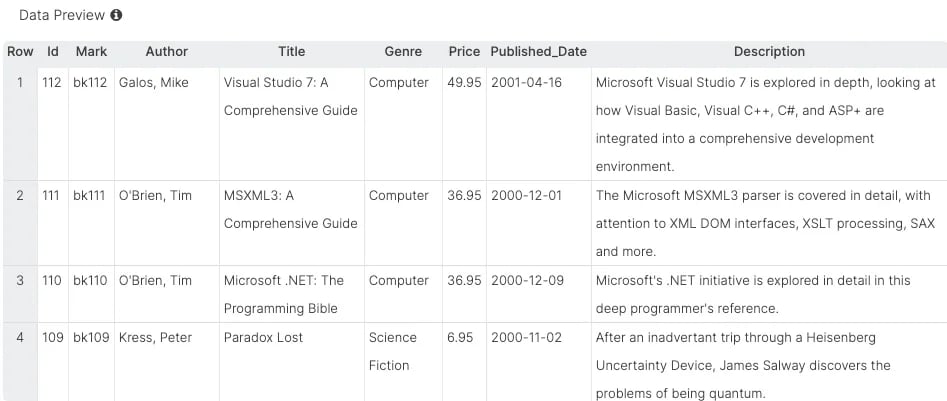 파일 및 API 응답에서 XML을 구문 분석하여 테이블 형식 구조로 변환하는 것은 데이터를 검색하는 데 중요합니다. 또한 다른 데이터 세트와의 블렌딩을 통해 데이터 분석을 더욱 쉽게 할 수 있습니다.
**요약**
신뢰할 수 있는 문서 기반 정보 전송으로 XML 기반 파일과 API를 유스 케이스에서 자주 볼 수 있습니다.
Xplenty는 이러한 XML 데이터를 쉽게 처리할 수 있는 기능을 제공합니다. 꼭 [Xplenty](https://try.integrate.io/kr-demo/) 무료 평가판을 신청해 보세요.
파일 및 API 응답에서 XML을 구문 분석하여 테이블 형식 구조로 변환하는 것은 데이터를 검색하는 데 중요합니다. 또한 다른 데이터 세트와의 블렌딩을 통해 데이터 분석을 더욱 쉽게 할 수 있습니다.
**요약**
신뢰할 수 있는 문서 기반 정보 전송으로 XML 기반 파일과 API를 유스 케이스에서 자주 볼 수 있습니다.
Xplenty는 이러한 XML 데이터를 쉽게 처리할 수 있는 기능을 제공합니다. 꼭 [Xplenty](https://try.integrate.io/kr-demo/) 무료 평가판을 신청해 보세요.