> ## Documentation Index
> Fetch the complete documentation index at: https://www.integrate.io/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# ETL: Database Destination
> Configure the Database destination to write data into PostgreSQL, MySQL, SQL Server, Oracle, or DB2 tables in your Integrate.io ETL pipeline.
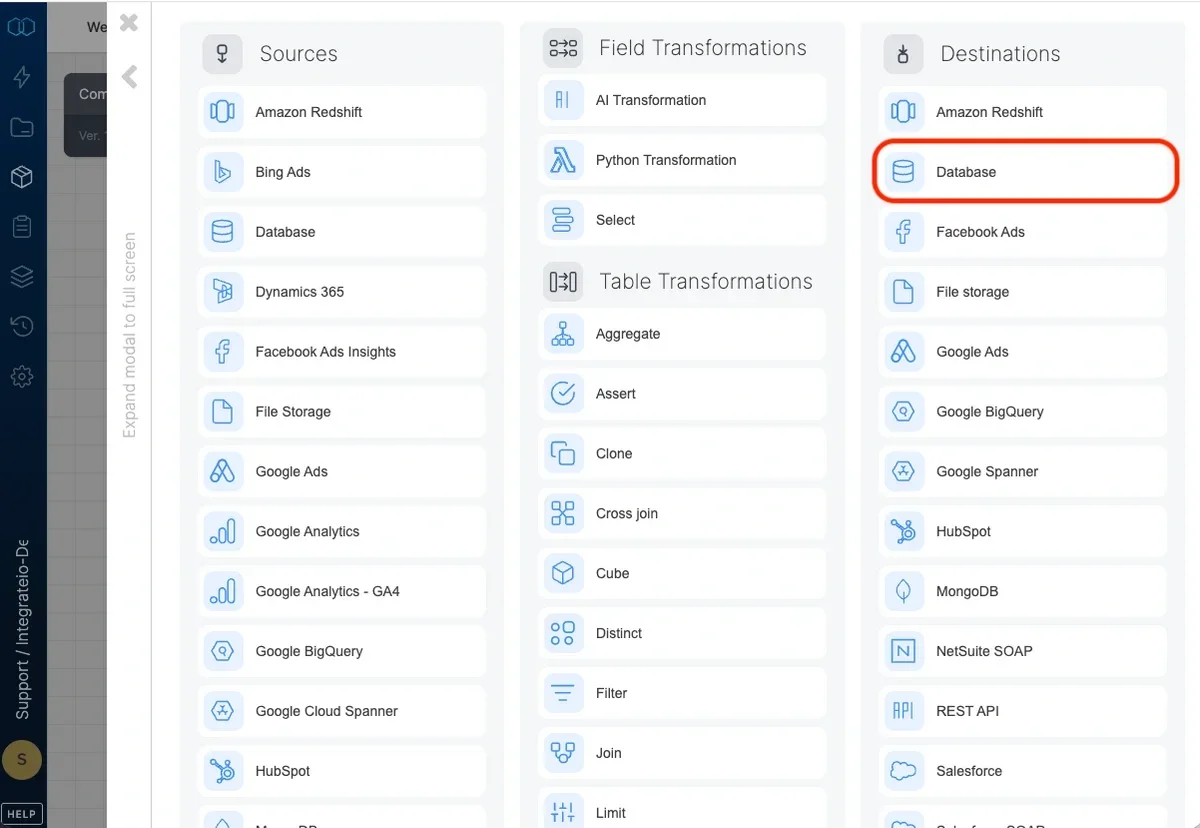 ## Connection
Select an existing database connection or create a new one (for more information, see [Allow Integrate.io ETL access to my database server](/docs/etl/allowing-integrateio-etl-access-to-my-server-behind-a-firewall/)).
## Destination Properties
* **Target schema** - the target table's schema. If empty, the default schema is used.
* **Target table** - the name of the target table in your database. By default, if the table doesn't exist, it will be created automatically.
* **Automatically create table if it doesn't exist** - if unchecked and the table doesn't exist, the job fails.
* **Automatically add missing columns** - when checked, the job will check if each of the specified columns exist in the table and if one does not exist, it will add it. Keep in mind that if there are a very large number of fields, this could impact job run time. Key columns can't be automatically added to a table.
### Operation type
## Connection
Select an existing database connection or create a new one (for more information, see [Allow Integrate.io ETL access to my database server](/docs/etl/allowing-integrateio-etl-access-to-my-server-behind-a-firewall/)).
## Destination Properties
* **Target schema** - the target table's schema. If empty, the default schema is used.
* **Target table** - the name of the target table in your database. By default, if the table doesn't exist, it will be created automatically.
* **Automatically create table if it doesn't exist** - if unchecked and the table doesn't exist, the job fails.
* **Automatically add missing columns** - when checked, the job will check if each of the specified columns exist in the table and if one does not exist, it will add it. Keep in mind that if there are a very large number of fields, this could impact job run time. Key columns can't be automatically added to a table.
### Operation type
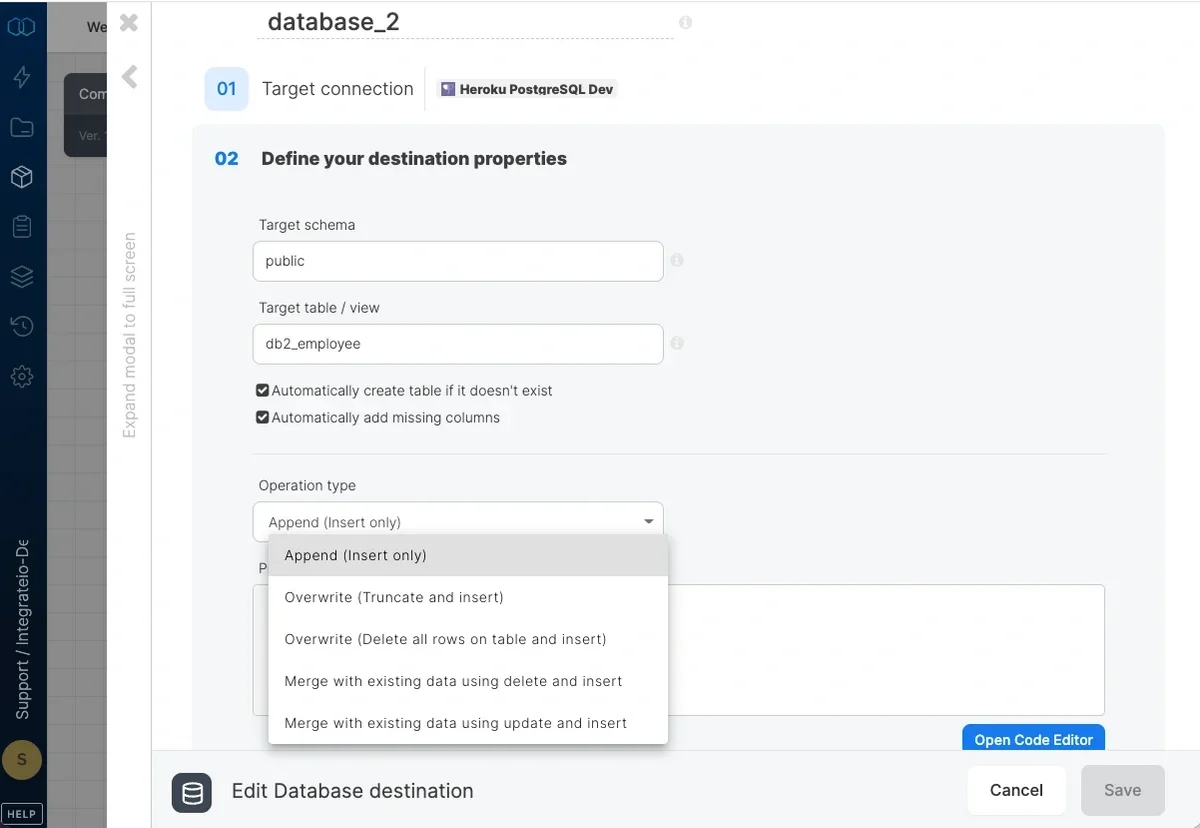 * **Append (Insert only)** - default behavior. Data will only be appended to the target table
* **Overwrite (Truncate and insert)** - truncate the target table before data is inserted into the target table. There may be limitations on whether truncate can be used on the target table, depending on the destination database platform.
* **Overwrite (Delete all rows on table and insert)** - deletes all of the target table before the data flow executes. If a truncate statement can't be executed on the target table due to permissions or other constraints, you can use this instead. This operation does not clear the schema.
* **Merge with existing data using delete and insert** - incoming data is merged with existing data in the table by deleting target table data that exists in both the data sets and then inserting all the incoming data into the target table. Requires setting the merge keys correctly in field mapping. Merge is done in the following manner:
First transaction - A staging table is created with a primary key according to your key mapping in the database's default schema.
Second transaction - The dataflow's output is bulk copied into the staging table.
Third transaction - Rows with keys that exist in the staging table are deleted from the target table. All rows in the staging table are inserted into the target table. The staging table is deleted.
* **Merge with existing data using update and insert** - incoming data is merged with existing data in the table by updating existing data and inserting new data. Requires setting the merge keys correctly in field mapping. Merge is done in the following manner:
First transaction - A staging table is created with a primary key according to your key mapping in the database's default schema.
Second transaction - The dataflow's output is bulk copied into the staging table.
Third transaction - Database specific command is issued to update existing records and insert. The staging table is deleted.
| Platform | SQL command |
| :------------------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| PostgreSQL (9.5+) | `sql INSERT INTO ("k1","c2",...,"cn") SELECT "k1","c2",...,"cn" FROM ON CONFLICT ("k1") DO UPDATE SET "c2" = excluded."c2", ... "cn" = excluded."cn"; ` |
| MySQL | ``sql INSERT INTO (\`k1\`, \`c2\`, ..., \`cn\`) SELECT \`k1\`, \`k2\`, \`c2\`, \`c3\`, \`c4\` FROM AS stg ON DUPLICATE KEY UPDATE \`c2\` = stg.\`c2\`, ... \`cn\` = stg.\`cn\`; `` |
| Microsoft SQL Server | `sql MERGE INTO as tgt USING as stg ON tgt."k1" = stg."k1" WHEN MATCHED THEN UPDATE SET tgt."c2" = stg."c2", ... tgt."cn" = stg."cn" WHEN NOT MATCHED BY TARGET THEN INSERT ("k1","c2",...,"c4") VALUES (stg."k1",stg."c2",...,stg."c4"); ` |
| Oracle | `sql MERGE INTO AS tgt USING AS stg ON (tgt."k1" = stg."k1") WHEN MATCHED THEN UPDATE SET tgt."c2" = stg."c2", ... tgt."cn" = stg."cn" WHEN NOT MATCHED THEN INSERT ("k1",c2",...,"cn") VALUES (stg."k1",stg."c2",...,stg."cn"); ` |
| Amazon Redshift | `sql START TRANSACTION; UPDATE SET c2 = .c2, ... cn = .cn FROM WHERE ."k1" = ."k1"; DELETE FROM USING WHERE ."k1" = ."k1"; INSERT INTO ("k1","k2","c2",...,"cn") SELECT "k1","c2",...,"cn" FROM ; COMMIT; ` |
| DB2 | `sql MERGE INTO AS tgt USING AS stg ON (tgt."k1" = stg."k1") WHEN MATCHED THEN UPDATE SET tgt."c2" = stg."c2", ... tgt."cn" = stg."cn" WHEN NOT MATCHED THEN INSERT ("k1",c2",...,"cn") VALUES (stg."k1",stg."c2",...,stg."cn"); ` |
| SAP HANA | `UPDATE SET c2 = .c2, ... cn = .cn FROM WHERE ."k1" = ."k1"; DELETE FROM USING WHERE ."k1" = ."k1"; INSERT INTO ("k1","k2","c2",...,"cn") SELECT "k1","c2",...,"cn" FROM ;` |
**Note:**
* The incoming data must have unique values in the key fields you selected. A possible workaround for this issue can be to use a Limit component and add the key field/s as a partition and limit it to 1 to remove duplicates.
* When executing **Merge** operation in **DB2** database, admin-level permission is required. Please use one of the following authorities:
* SYSADM
* SYSCTRL
* SYSMAINT
* DBADM
* SQLADM
* CONTROL
* EXECUTE
* DATAACCESS
* When inserting data to Oracle DB destination with "add missing column" checked. We might need a specific permission to `dba_tab_columns` by executing either\
`GRANT SELECT_CATALOG_ROLE TO your_username` or `GRANT SELECT ANY DICTIONARY TO your_username`. (Reference: [Oracle 11g Role and User management](https://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_9013.htm#SQLRF01603), [Oracle 11g GRANT command documentation](https://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_9013.htm))
### Pre and Post action SQL
* **Append (Insert only)** - default behavior. Data will only be appended to the target table
* **Overwrite (Truncate and insert)** - truncate the target table before data is inserted into the target table. There may be limitations on whether truncate can be used on the target table, depending on the destination database platform.
* **Overwrite (Delete all rows on table and insert)** - deletes all of the target table before the data flow executes. If a truncate statement can't be executed on the target table due to permissions or other constraints, you can use this instead. This operation does not clear the schema.
* **Merge with existing data using delete and insert** - incoming data is merged with existing data in the table by deleting target table data that exists in both the data sets and then inserting all the incoming data into the target table. Requires setting the merge keys correctly in field mapping. Merge is done in the following manner:
First transaction - A staging table is created with a primary key according to your key mapping in the database's default schema.
Second transaction - The dataflow's output is bulk copied into the staging table.
Third transaction - Rows with keys that exist in the staging table are deleted from the target table. All rows in the staging table are inserted into the target table. The staging table is deleted.
* **Merge with existing data using update and insert** - incoming data is merged with existing data in the table by updating existing data and inserting new data. Requires setting the merge keys correctly in field mapping. Merge is done in the following manner:
First transaction - A staging table is created with a primary key according to your key mapping in the database's default schema.
Second transaction - The dataflow's output is bulk copied into the staging table.
Third transaction - Database specific command is issued to update existing records and insert. The staging table is deleted.
| Platform | SQL command |
| :------------------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| PostgreSQL (9.5+) | `sql INSERT INTO ("k1","c2",...,"cn") SELECT "k1","c2",...,"cn" FROM ON CONFLICT ("k1") DO UPDATE SET "c2" = excluded."c2", ... "cn" = excluded."cn"; ` |
| MySQL | ``sql INSERT INTO (\`k1\`, \`c2\`, ..., \`cn\`) SELECT \`k1\`, \`k2\`, \`c2\`, \`c3\`, \`c4\` FROM AS stg ON DUPLICATE KEY UPDATE \`c2\` = stg.\`c2\`, ... \`cn\` = stg.\`cn\`; `` |
| Microsoft SQL Server | `sql MERGE INTO as tgt USING as stg ON tgt."k1" = stg."k1" WHEN MATCHED THEN UPDATE SET tgt."c2" = stg."c2", ... tgt."cn" = stg."cn" WHEN NOT MATCHED BY TARGET THEN INSERT ("k1","c2",...,"c4") VALUES (stg."k1",stg."c2",...,stg."c4"); ` |
| Oracle | `sql MERGE INTO AS tgt USING AS stg ON (tgt."k1" = stg."k1") WHEN MATCHED THEN UPDATE SET tgt."c2" = stg."c2", ... tgt."cn" = stg."cn" WHEN NOT MATCHED THEN INSERT ("k1",c2",...,"cn") VALUES (stg."k1",stg."c2",...,stg."cn"); ` |
| Amazon Redshift | `sql START TRANSACTION; UPDATE SET c2 = .c2, ... cn = .cn FROM WHERE ."k1" = ."k1"; DELETE FROM USING WHERE ."k1" = ."k1"; INSERT INTO ("k1","k2","c2",...,"cn") SELECT "k1","c2",...,"cn" FROM ; COMMIT; ` |
| DB2 | `sql MERGE INTO AS tgt USING AS stg ON (tgt."k1" = stg."k1") WHEN MATCHED THEN UPDATE SET tgt."c2" = stg."c2", ... tgt."cn" = stg."cn" WHEN NOT MATCHED THEN INSERT ("k1",c2",...,"cn") VALUES (stg."k1",stg."c2",...,stg."cn"); ` |
| SAP HANA | `UPDATE SET c2 = .c2, ... cn = .cn FROM WHERE ."k1" = ."k1"; DELETE FROM USING WHERE ."k1" = ."k1"; INSERT INTO ("k1","k2","c2",...,"cn") SELECT "k1","c2",...,"cn" FROM ;` |
**Note:**
* The incoming data must have unique values in the key fields you selected. A possible workaround for this issue can be to use a Limit component and add the key field/s as a partition and limit it to 1 to remove duplicates.
* When executing **Merge** operation in **DB2** database, admin-level permission is required. Please use one of the following authorities:
* SYSADM
* SYSCTRL
* SYSMAINT
* DBADM
* SQLADM
* CONTROL
* EXECUTE
* DATAACCESS
* When inserting data to Oracle DB destination with "add missing column" checked. We might need a specific permission to `dba_tab_columns` by executing either\
`GRANT SELECT_CATALOG_ROLE TO your_username` or `GRANT SELECT ANY DICTIONARY TO your_username`. (Reference: [Oracle 11g Role and User management](https://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_9013.htm#SQLRF01603), [Oracle 11g GRANT command documentation](https://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_9013.htm))
### Pre and Post action SQL
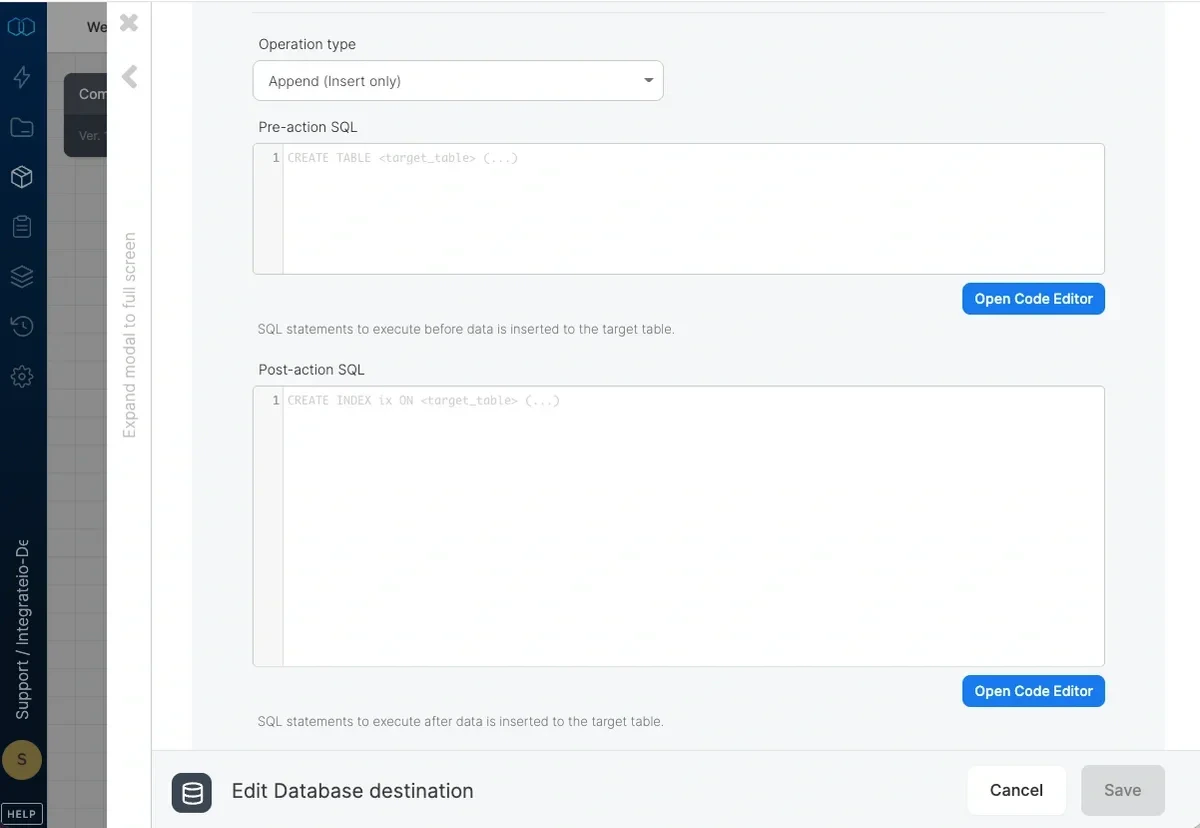 * **Pre-action SQL** - SQL code to execute before inserting the data into the target table. If a merge operation is selected, the sql code is executed before the staging table is created.
* **Post-action SQL** - SQL code to execute after inserting the data into the target table. If a merge operation is selected, the sql code is executed after the staging table is merged into the target table.
**Note**:
Post-action SQL will only executed after successfully writing data to the table. If the jobs fails - the action will not proceed.
### Advanced options
* **Pre-action SQL** - SQL code to execute before inserting the data into the target table. If a merge operation is selected, the sql code is executed before the staging table is created.
* **Post-action SQL** - SQL code to execute after inserting the data into the target table. If a merge operation is selected, the sql code is executed after the staging table is merged into the target table.
**Note**:
Post-action SQL will only executed after successfully writing data to the table. If the jobs fails - the action will not proceed.
### Advanced options
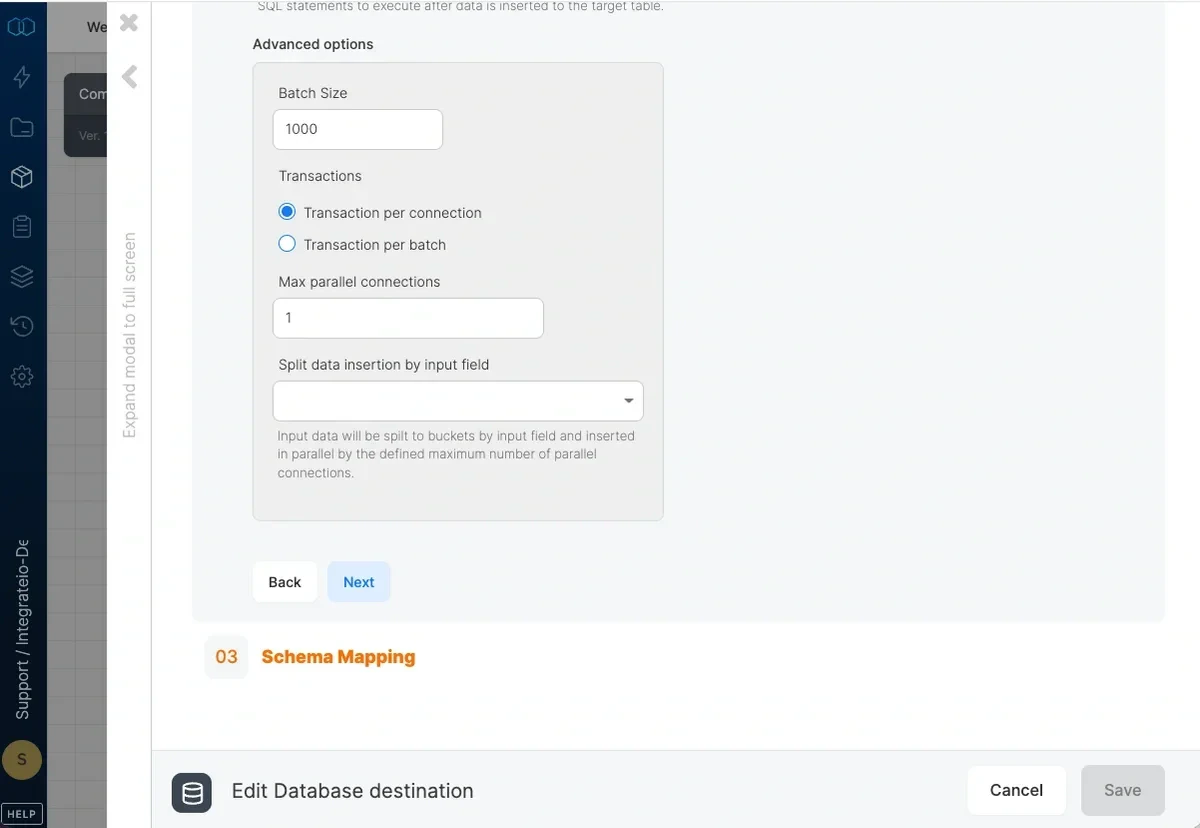 * **Batch size** - number of records that are inserted to the database in each batch (default 1000).
* **Transactions** - by default, each connection to the database will use a single transaction. If "Transaction per batch" is selected, each batch will be committed on its own which may lead to partial data in the target table in case the job fails.
* **Max parallel connections** - maximum number of concurrent connections to open when writing to the database (1 by default).
* **Split data insertion by input field** - when using more than one connection, this field will be used to split the data to the different connections. Pick a field with low density (a unique key is best) to make sure that data split isn't skewed.
* **Insert values to identity column (SQL Server)** - Only available if SQL server connection is selected on the component. SQL Server does not allow inserting explicit values to **identity column**. Enabling this will set **IDENTITY\_INSERT** to **ON** before the query to insert values to identity column.
## Schema Mapping
* **Batch size** - number of records that are inserted to the database in each batch (default 1000).
* **Transactions** - by default, each connection to the database will use a single transaction. If "Transaction per batch" is selected, each batch will be committed on its own which may lead to partial data in the target table in case the job fails.
* **Max parallel connections** - maximum number of concurrent connections to open when writing to the database (1 by default).
* **Split data insertion by input field** - when using more than one connection, this field will be used to split the data to the different connections. Pick a field with low density (a unique key is best) to make sure that data split isn't skewed.
* **Insert values to identity column (SQL Server)** - Only available if SQL server connection is selected on the component. SQL Server does not allow inserting explicit values to **identity column**. Enabling this will set **IDENTITY\_INSERT** to **ON** before the query to insert values to identity column.
## Schema Mapping
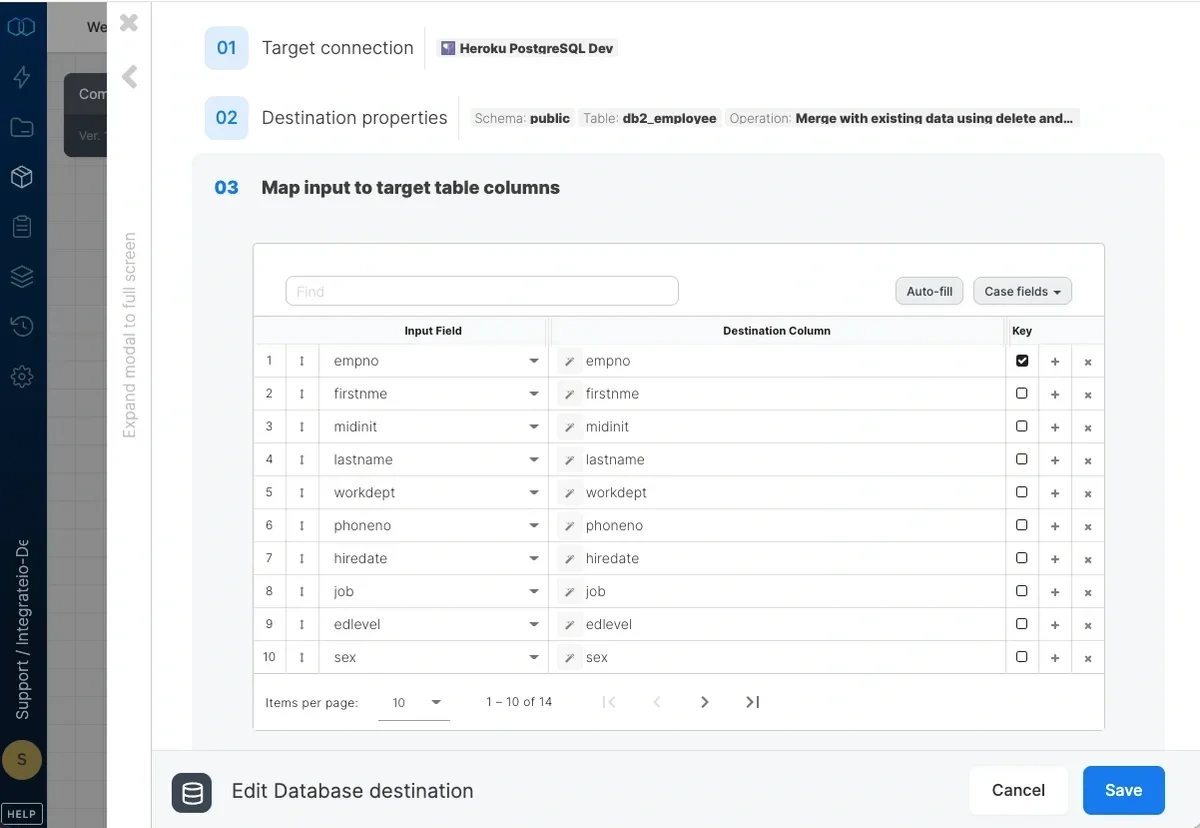 Map the dataflow fields to the target table's columns. Columns defined as key will be used as the sort key when Integrate.io ETL creates the table. If merge operation is used, you must select at least a field or multiple fields as keys, which will be used to uniquely identify rows in the table for the merge operation.
The data types in Integrate.io ETL are automatically mapped as follows when the table is created automatically. Note that since Integrate.io ETL doesn't have a notion of maximum string length, the string columns are created with the maximum length allowed in the database.
| **Integrate.io ETL** | **PostgreSQL** | **MySQL** | **Microsoft SQL Server** | **DB2** | **SAP HANA** |
| :------------------- | :---------------------------- | :---------------------------------------------------- | :------------------------------------------------------------- | :-------------------- | :-------------------------------------------------------- |
| String | varchar, char, text, interval | varchar, nvarchar, text, | varchar, nvarchar, text, ntext | varchar, char | varchar, nvarchar, alphanum, shorttext, clob, nclob, text |
| Integer | smallint, int | bit, bool, tinyint, smallint, mediumint, int, integer | tinyint, smallint, int | smallint, int | tinyint, smallint, integer |
| Long | bigint | bigint | bigint | bigint | bigint |
| Float | decimal, real | decimal, float | decimal, numeric, float | double precision | decimal, real, smalldecimal |
| Double | double precision | double | real | double precision | double |
| DateTime | timestamp, date, time | date, datetime, timestamp, time | datetime, datetime2, smalldatetime, date, time, datetimeoffset | timestamp, date, time | date, time, seconddate, timestamp, longdate, secondtime |
| Boolean | TINYINT(1) | BOOLEAN | BIT | BOOLEAN | BOOLEAN |
## Related
**Note:**
Use the ToDate function to cast a datetime string expression to datetime data type. Note that a datetime with timezone offset value will be adjusted to UTC when inserted into a database
## Automatically creating and altering destination table
Integrate.io ETL can automatically create the destination table for you if it doesn't exist and it can also append columns to an existing table. If you define columns as key (regardless of the operation type), Integrate.io ETL defines them as the primary key in a new table. The data types in Integrate.io ETL are automatically mapped as follows. Note that since Integrate.io ETL doesn't have a notion of maximum string length, the string columns are created with the maximum length allowed in the database.
| **Integrate.io ETL** | **PostgreSQL** | **MySQL** | **Microsoft SQL Server** | **Oracle** | **DB2** |
| :---------------------- | :--------------- | :------------ | :----------------------- | :------------- | :--------------- |
| String (key column) | VARCHAR(100) | NVARCHAR(100) | NVARCHAR(100) | NVARCHAR2(100) | VARCHAR(100) |
| String (non key column) | VARCHAR(65535) | TEXT | NVARCHAR(MAX) | NCLOB | VARCHAR(32672) |
| Integer | INT | INT | INT | NUMBER | INT |
| Long | BIGINT | BIGINT | BIGINT | NUMBER | BIGINT |
| Float | REAL | FLOAT | REAL | NUMBER | DOUBLE PRECISION |
| Double | DOUBLE PRECISION | DOUBLE | FLOAT | NUMBER | DOUBLE PRECISION |
| DateTime | TIMESTAMP | DATETIME | DATETIME | TIMESTAMP | TIMESTAMP |
| Boolean | BOOLEAN | TINYINT(1) | BIT | NUMBER(1) | BOOLEAN |
Map the dataflow fields to the target table's columns. Columns defined as key will be used as the sort key when Integrate.io ETL creates the table. If merge operation is used, you must select at least a field or multiple fields as keys, which will be used to uniquely identify rows in the table for the merge operation.
The data types in Integrate.io ETL are automatically mapped as follows when the table is created automatically. Note that since Integrate.io ETL doesn't have a notion of maximum string length, the string columns are created with the maximum length allowed in the database.
| **Integrate.io ETL** | **PostgreSQL** | **MySQL** | **Microsoft SQL Server** | **DB2** | **SAP HANA** |
| :------------------- | :---------------------------- | :---------------------------------------------------- | :------------------------------------------------------------- | :-------------------- | :-------------------------------------------------------- |
| String | varchar, char, text, interval | varchar, nvarchar, text, | varchar, nvarchar, text, ntext | varchar, char | varchar, nvarchar, alphanum, shorttext, clob, nclob, text |
| Integer | smallint, int | bit, bool, tinyint, smallint, mediumint, int, integer | tinyint, smallint, int | smallint, int | tinyint, smallint, integer |
| Long | bigint | bigint | bigint | bigint | bigint |
| Float | decimal, real | decimal, float | decimal, numeric, float | double precision | decimal, real, smalldecimal |
| Double | double precision | double | real | double precision | double |
| DateTime | timestamp, date, time | date, datetime, timestamp, time | datetime, datetime2, smalldatetime, date, time, datetimeoffset | timestamp, date, time | date, time, seconddate, timestamp, longdate, secondtime |
| Boolean | TINYINT(1) | BOOLEAN | BIT | BOOLEAN | BOOLEAN |
## Related
**Note:**
Use the ToDate function to cast a datetime string expression to datetime data type. Note that a datetime with timezone offset value will be adjusted to UTC when inserted into a database
## Automatically creating and altering destination table
Integrate.io ETL can automatically create the destination table for you if it doesn't exist and it can also append columns to an existing table. If you define columns as key (regardless of the operation type), Integrate.io ETL defines them as the primary key in a new table. The data types in Integrate.io ETL are automatically mapped as follows. Note that since Integrate.io ETL doesn't have a notion of maximum string length, the string columns are created with the maximum length allowed in the database.
| **Integrate.io ETL** | **PostgreSQL** | **MySQL** | **Microsoft SQL Server** | **Oracle** | **DB2** |
| :---------------------- | :--------------- | :------------ | :----------------------- | :------------- | :--------------- |
| String (key column) | VARCHAR(100) | NVARCHAR(100) | NVARCHAR(100) | NVARCHAR2(100) | VARCHAR(100) |
| String (non key column) | VARCHAR(65535) | TEXT | NVARCHAR(MAX) | NCLOB | VARCHAR(32672) |
| Integer | INT | INT | INT | NUMBER | INT |
| Long | BIGINT | BIGINT | BIGINT | NUMBER | BIGINT |
| Float | REAL | FLOAT | REAL | NUMBER | DOUBLE PRECISION |
| Double | DOUBLE PRECISION | DOUBLE | FLOAT | NUMBER | DOUBLE PRECISION |
| DateTime | TIMESTAMP | DATETIME | DATETIME | TIMESTAMP | TIMESTAMP |
| Boolean | BOOLEAN | TINYINT(1) | BIT | NUMBER(1) | BOOLEAN |