
今日のデジタル時代において、データウェアハウスは企業にとって極めて重要な礎石となっています。データウェアハウスは、組織の膨大なデータを格納するデジタルレポジトリと定義され、データの安全な保管だけでなく、データへの簡単なアクセスの実現など、「保管庫」と「図書館」の両方の役割を果たします。また、企業のデータへのアクセスは、ビジネスの成功に不可欠でであり、データウェアハウスの市場規模は、2023年から2029年にかけて585億4000万ドルにまで拡大すると予想されていますが、この急成長の原動力は何なのでしょうか?
そこで、データウェアハウスの複雑な世界と、現代のビジネスの成功に不可欠なその役割に迫りましょう。
以下に、この記事から得られた重要なポイントをいくつか挙げましょう:
- データウェアハウスは、ビジネスのインサイトを強化するのに多様なデータを集約する。
- ウェアハウスの種類は、ユーザーグループ用の「データマート」から包括的な「エンタープライズデータウェアハウス」まで多岐にわたる。
- データウェアハウスは構造化データに焦点を当て、データレイクは非構造化コンテンツを扱う。
- データレイクハウスは、データレイクとウェアハウスの利点を融合し、多目的なデータ保存を実現する。
- クラウドベースのソリューションと自動化された ETL ツールへの移行で、リアルタイムの分析が強化される。
このガイドで、 クラウドベースのソリューションからオープンソースやオンプレミスのオプションまで、データウェアハウスとは何かがわかると同時に、ビジネスに最適なソリューションをいくつか見ることができます。また、自動化されたETL ツールで、どのようにより効率的なデータワークフローを構築できるかを探っていきましょう。
目次


データを統一化して革新を起こすデータチームへ
ソリューションエンジニアによる個別デモと30分のQ&Aセッションを受けることができます
データウェアハウスとは
データウェアハウスは、多様なデータソースからの情報を集約、保存、処理し、BI(ビジネスインテリジェンス)システムが利用できるようにする(統合された単一の全体として照会できるようにする)システムです。
「データウェアハウスとは何か」という問いに取り組む際に、「BI プラットフォーム」という言葉も重要です。BI(ビジネスインテリジェンス)プラットフォームは、データウェアハウス内の集計データにアクセスし、クエリと分析を行うことで、利益を高めるインサイトを生み出します。
データ ウェアハウスの問題は、最近、データと分析に携わる多くの人々の関心事になっていますが、それには十分な理由があります。AI(人工知能)や ML(機械学習)によるインサイトは、Google、Amazon、Facebook、Microsoft のような大手テック企業だけしか利用できなかった時代がありましたが、現在では、誰でもデータウェアハウスを構築し、価値あるML のインサイトを手頃な価格で得ることができますからね。
データウェアハウスの目的
データウェアハウスは、企業が全データにアクセスして分析し、最も正確なビジネスインサイトと予測モデルを導き出すことを主な目的としています。
データウェアハウスと BI ソリューションは、(1)その BI インサイトが企業に競争上の優位性をもたらし、(2)より多くの企業が利用していることから、現在、これまで以上に不可欠なものとなっています。なのでこのような先進的なデータソリューションを取り入れない企業は、深刻な不利益を被ることになるでしょう。
データウェアハウスの種類
以下に、データウェアハウスの主な種類を挙げましょう:
- データマート: ビジネス部門など共通のニーズを持つユーザーグループに関連するデータを保持するレポジトリ。
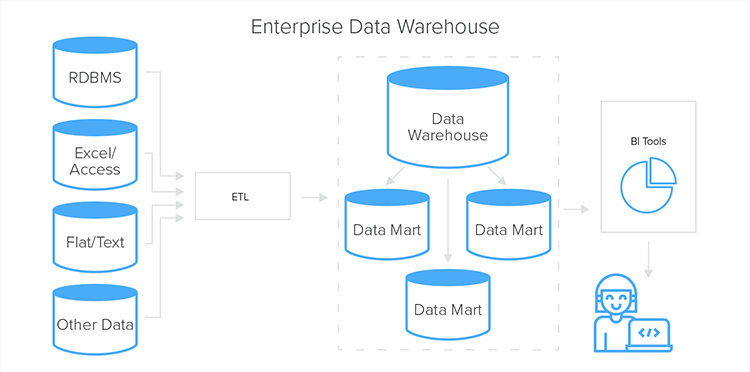
- エンタープライズデータウェアハウス: 複数のソースからの標準化されたデータを含むレポジトリ。データはウェアハウスに取り込まれる前に変換されるため、ウェアハウスのデータは清浄化され、関連するビジネス目的のために準備されていることになる。
- 運用データストア(ODS): ODS(運用データストア)には、複数のトランザクションシステムから最新のデータが格納され、運用レポーティングに使用される。また、長期的な分析のためにエンタープライズデータウェアハウスにデータを供給する。
データウェアハウスの仕組み
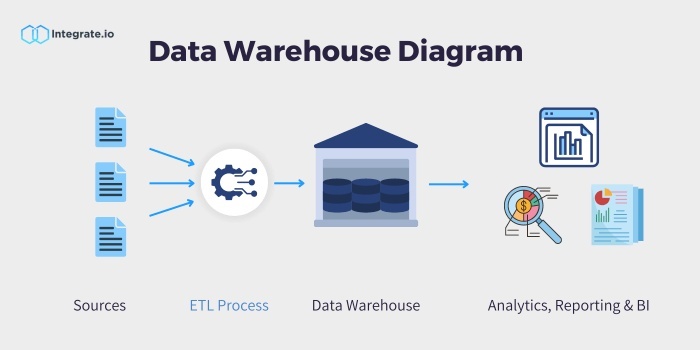
データウェアハウスが何であるかを知るだけでなく、どのように機能するのかを理解しておくといいですね。データウェアハウスは、組織全体の多くのデータソースから情報を集めます。そしてデータはそのシステムから抽出され、理想的な形式に変換された後、多くの場合 ETL(抽出、変換、格納)と呼ばれる方法を使ってデータウェアハウスに格納され、このデータの中央レポジトリは、分析やレポーティングに使用することができます。
データウェアハウスの例
例えば会社の全部門のために、次年度のワークステーションとそれに必要なコンポーネントの発注台数を決めないといけないとしましょう。このような決定には、以下のデータを俯瞰的に見る必要があります。
- 各部門の従業員数
- 従業員が使用しているワークステーションとその付属品 (モニター、マウス、キーボード、机、椅子など)
- 各従業員の役割
- 従業員の役割に応じて、その責任を果たすのに必要な技術/設備
- ワークステーション一式に必要な各種コンポーネントの価格
- 大型機器の購入には一括割引の可能性あり
- 機器を提供するさまざまなベンダー
- 機器の消耗率
- 従業員の離職率
- 従業員の拡大または縮小を予測する予測
- 現在の予算の制限、ガイドライン、目標
データウェアハウスでは、このような情報をさまざまなソースから集める代わりに、一箇所ですぐに利用できるようにすることで、分析や理解がしやすいレポーティングモデルに整理することができます。
もちろん、こうしたインサイトを引き出すには、BI プラットフォームとデータウェアハウスを組み合わせて、Integrate.io のような効果的なデータ統合プラットフォームへの投資が必要になるでしょう。
よく使われているデータウェアハウスのプラットフォーム
最もよく使われているデータウェアハウスのプラットフォームには次のようなものがあります:
- Snowflake
- Amazon Redshift
- Google BigQuery
- IBM Db2
構造化データと非構造化データ
データウェアハウスは、主にテーブル、行、列などの特定の方法で編成された構造化データを格納します。構造化データには、Oracle RDBMS、IBM DB2、Microsoft SQL Server、Teradata、MySQL、ADABAS、Microsoft Access などの RDBMS(リレーショナルデータベースシステム)にある情報が含まれ、そのデータは、会計ソフト、給与記録、広告、倉庫管理、配送、フルフィルメントなどに関連している可能性があります。
一方、非構造化データには、テキストやビデオのような特定のフォーマットがありません。データウェアハウスは構造化されたデータしか扱えませんが、世の中のほとんどの情報は非構造化データ、つまり定義された組織やスキーマを持たないデータに分類されます。
非構造化データの量は年々増加しており、最近の報告によると、2025年までに、世界には1750億テラバイトの非構造化データが存在する可能性があるようです。非構造化データを取り込む必要性はかつてないほど高まっており、データウェアハウスと統合することで、企業はより優れた、より競争力のあるインサイトを得ることができます。なので、非構造化データの量が増えるにつれて、企業は大量の生の非構造化データを保存するために設計されたデータレイクのコンセプトを模索し始めています。
データレイク
加工や精製されたデータを保管するデータウェアハウスとは異なり、データレイクは膨大な量の生データをそのままの形式で保管し、そのデータは構造化、半構造化、非構造化のいずれでも構いません。そして、組織がデータレイクを使うのは、データがどのように使用されるかを知る前にデータを保存する必要がある場合です。
そして、BI ツールが非構造化データから貴重なインサイトを抽出できる可能性があるため、この非構造化データは貴重です。たとえば、特定の語句を検索することで、大量の非構造化テキストをクエリできますからね。
非構造化データをすぐに利用しなくても、後で役に立つかもしれません。ただ問題は、従来のデータウェアハウスでは、非構造化情報を保存したり扱うことができないということです。そこで「データレイク」の登場となります。
データレイクは従来のデータウェアハウスと連携し、膨大な量の非構造化データを保存します。あらゆるタイプの情報をデータレイクにインポートし、ゆるやかにカタログ化することができます( 情報を別のファイルフォルダーにダンプするようなものですね)。また、データレイクは、IoTデバイスのネットワーク、SNSサイト、メールアカウント、モバイルアプリからのデータなど、複数のソースからリアルタイムで生の情報を受け入れます。
データレイクの利点は他にも以下のようなものがあります:
- 膨大な非構造化データプールへのアクセス: データレイクにより、ML ツールは、膨大な非構造化データのプールをクロールし、カタログ化し、インデックス化して、過去のグラフ、予測モデル、「処方範囲」提案の形でインサイトを生み出すことができる。データレイクと連携する ML プラットフォームには、Presto、Apache Spark、Apache Hadoop、その他の BI ソリューションがある。
- 非構造化データの分析から得られる、現状を打破するようなインサイト: これまでアクセスできなかった非構造化データの分析から得られるインサイトは、示唆に富んでおり、AI(人工知能)とML(機械学習)は、地理空間情報からヒトゲノムの塩基配列決定に至るまで、大量の非構造化データを扱う鍵となり得る。
- より貴重な研究:これまで立ち入り禁止だったデータへのアクセスを ML ツールに提供すると、収益機会が明らかになる可能性がある。 たとえば、より多くの CRM (顧客管理システム)のデータを組み込んで、顧客がどのような戦略に反応し、どの戦略を拒否したかを理解することができたり、アイデアを市場に出す前に、仮説や仮定をテストすることもできる。 最終的に、IoT デバイスによって収集された製造データを確認することで、企業はリアルタイムのレポートと即時対応を通じてプロセスの効率を大幅に向上させることができる。
最後に注意しておきますが、データ レイクとデータ ウェアハウスを併用してビジネス上のインサイトを引き出すことは、まだ比較的新しいことです。 なので、このような高度な BI 戦略を使用する前に、強力なサポート チームが配置されていることを確認してください。
データレイクハウス
データの保存に関するもう 1 つのオプションは、「データ レイクハウス」と呼ばれる、[データ レイク]と[データ ウェアハウス]を組み合わせたものです。
データ レイクハウスは、データ レイクやデータ ウェアハウスに伴う以下のような不満の一部に対処します。
- データ ウェアハウスは、ビジネスに精通したユーザーが読み取ることができ、他のアプリケーションにも使用できるような、厳密に構造化されたデータを特徴としているが、ウェアハウスには、特にスキーマやコンピューティングとストレージの緊密な結合に関して制限と制約がある。
- データレイクは、データサイエンティストとモデルに分析のための豊富なオプションを提供するが、意思決定者が必要とする決定的で実用的な情報を提供しない可能性がある。
「データ レイクハウス」は、両方のモデルの長所を取り入れようとする折衷的な試みであり、「 データ レイクのスケーラビリティと俊敏性」を備えた「データ ウェアハウスの読みやすさと構造」を提供します。
詳細については、データ レイクハウスに関するこちらの記事をご覧ください
データを統一化して革新を起こすデータチームへ
ソリューションエンジニアによる個別デモと30分のQ&Aセッションを受けることができます
最新のデータ ウェアハウス のテクノロジー
データレイクハウスの テクノロジーは、データの管理と分析に優れた柔軟性を提供しますが、これが唯一のオプションではありません。 最新のデータ ウェアハウス テクノロジーを活用することで、大量のデータを迅速かつ効率的に処理できる強固なインフラストラクチャを企業に提供できます。
例えば、クラウドベースのデータ ウェアハウスはオンプレミス ソリューションの代替手段を提供し、それによって企業はクラウド インフラストラクチャに伴う拡張性とコスト削減を活用できます。
クラウドベースのデータ ウェアハウス
以前は、データ ウェアハウスにはオンサイトの物理サーバーが必要でしたが、 最近では、企業はすでに情報システムをクラウドベースのデータ ウェアハウスに移行しているか、移行を検討しています。
クラウドベースのデータ ウェアハウスの利点は以下のとおりです:
- スタートアップ のコストがゼロ:以前は、オンサイトの物理サーバーのハードウェアを購入して設置するのは非常に高価だったが、 クラウドベースのデータ ウェアハウスだと、クラウドベースのサーバーを起動するときにハードウェアに投資する必要がない。インターネット経由で必要なサーバー構成を選択してサーバーを起動するだけで準備が完了し、 高価な機器を購入する代わりに、使った分だけ SaaS (サービスとしてのソフトウェア) 料金を支払う。
-
ほぼ即時の導入: データ ウェアハウスでは、以前は適切な機器を購入するために大変な準備が必要だったが、クラウドベースのデータ ウェアハウスでは、ニーズを正しく見積もっていない場合でも、サーバー構成を調整することでソリューションをアップグレードできる。 それによって、データ ソリューションを開始する前の複雑な準備が不要になる。
スケーラビリティとコスト弾力性:クラウドベースのデータ ウェアハウスのもう 1 つの経済的利点は、必要な分だけを必要なときに支払える点である。例えば、 夏の間に多くの複雑なクエリを実行する必要があるとしたら、夏の間はより多くの料金を支払うことになるが、残りの期間は、データの必要性が低いためそれほどコストはかからない。 データ統合ソリューションは、必要に応じてスケールアップまたはスケールダウンできるのである。 - より速く、より優れたインサイト:かつて企業は、アップグレードに投資する経済的な準備ができていなかったため、サーバー ハードウェアの速度の低下とストレージの壊滅的な制約に悩まされていたが、 クラウドベースのソリューションの弾力性により、「低速クエリ症候群」の脅威がなくなり、より速く優れた BI のインサイトが提供される。
- サーバーのメンテナンス コストの削減:クラウドベースのデータ ウェアハウス ユーザーは、自動化されたパッチ、アップグレード、セキュリティ アップデートを享受できる。 また、社内の技術チームが実装する必要があるタスクの多くも自動化される。それによって、サーバーのメンテナンス コストが削減され、技術チームやデベロッパーはより重要な問題について心配する必要がなくなる。
ちなみに、最もよく使われているクラウドベースのデータ ウェアハウスには、Redshift、Snowflake、Db2、Google BigQuery などがあり、 IBM、Microsoft Azure、Teradata、Oracle などの最も人気のあるオンサイト データ ウェアハウス ソリューションも、クラウドとオンサイトの機能を組み合わせたハイブリッド プラットフォームを開発しています。
さらに読む(英語): What to Consider When Selecting a Data Warehouse for Your Busines(ビジネスにデータ ウェアハウスを選択する際に考慮すべきこと)
自動 ETL ツール
自動 ETL (抽出、変換、格納) ツールは、企業がデータ ワークフローを効率化するために活用できるもう 1 つの最新のデータ ウェアハウス テクノロジーです。 ETL ツールを使うと、複数のソースから統合データベースに自動的かつ頻繁にデータを統合でき、それによって、企業はコストのかかる技術チームを必要とせずに、ウェアハウスに保存されている利用可能な全データにサッとアクセスして効果的に使えるようになります。
以前は、互換性のないデータ形式をデータ ウェアハウスに統合するには、手間もお金もかかる手作業によるコーディングでのプログラミングが必要でしたが、最近では、Integrate.io などのクラウドベースの ETL ツールを使って、さまざまな種類の構造化データと非構造化データをデータ ウェアハウスや BI ソリューションに統合できます。
自動 ETL ツールがあらゆる種類のデータを統合する方法
Integrate.io のような自動 ETL ツールの利点は以下のとおりです:
- 高速かつ簡単な接続:1 対 1 の手作業でコーディングされた統合では、特定のデータ ソースとデータ ウェアハウスの間に信頼性の高いデータ接続を確立するまでに数か月かかる場合があり、そのような接続を構築した後にそれを維持するには、さらに時間のかかる課題が生じるが、Integrate.io などのクラウドベースのデータ統合サービスには、Salesforce、Facebook、Google サービス、Excel、MySQL などのサービスから貴重なデータを即座に接続するための、事前に構築されたコネクタとアダプターが備わっている。
- より多くのデータにアクセス:以前は互換性のなかったデータを統合することで、データ ウェアハウスと BI ツールをより多くの情報に開放し、より優れた、より正確なレポートを作成して、より適切なビジネス上の意思決定をサポートする。
- リアルタイムの可用性:必要な BI のインサイトをより早く取得できるほど、より優れた意思決定者が組織を率いることができる。 競合他社がリアルタイム レポート システムを採用している場合、インサイトやレポートを1日に1回か 2回受け取るだけでは競争力は保たれず、このようなリアルタイムのレポートを実現するには、信頼性の高いデータ統合が最適な方法である。
- データの品質と整合性の向上:データ統合戦略で、さまざまな情報をデータ ウェアハウスに統合する際に、データの品質とデータの整合性を維持することができ、それによって、BI ソリューションがより正確なインサイトを提供できるようになる。
データウェアハウスの未来
今後、データレイクとデータウェアハウスの境界線は曖昧になっていき、リアルタイムでのアナリティクスと、より統合された BI プラットフォームに焦点が移っていくでしょう。また、AI とMLの発展に伴い、予測分析が BI の要となり、ウェアハウスからのデータを活用してトレンドを予測し、プロアクティブな意思決定を行うようになるでしょう。
データウェアハウスは、進化を続ける BI において不可欠なツールです。企業がより多くのデータを生成するにつれて、このデータを効率的に保存、分析、活用することが最も重要になり、データウェアハウスの最新トレンドとテクノロジーの把握が、企業が競争力を維持するためは欠かせません。
Integrate.io とデータウェアハウス
「データウェアハウスとは何か?」という質問に対して、良い回答ができたと思います。ここまでで、データウェアハウスについて、そしてなぜデータウェアハウスが現代のビジネスにおいて重要なのかについて、十分ご理解いただけたと思います。では今度は、データウェアハウスをセットアップして、さまざまな情報源をすべてそこに格納しないといけませんが、それは適切な人材とツールがないと、簡単にはいかないんです。
もし自身やチームが原因でデータウェアハウスや BI プラットフォームへの主要なデータストリームの統合が遅れていたら、Integrate.io がお手伝いします。Integrate.io は新しいデータ統合プラットフォームで、ETL とELT のテクノロジーを活用し、既存の全ビジネスデータにリンクします。
また、超高速 CDC(変更データキャプチャ)オプションにより、過去のデータの取り込みや、変更があった場合のみの更新ができます。それによって、より効率的なデータウェアハウスが促進され、BI ツールの有効性に影響を及ぼす可能性のある低速で不便なデータウェアハウスになるのを防ぐことができるのです。
さらに、リバース ETL は、データウェアハウスからデータを取得し、Salesforce などの他のシステムにアップロードすることができます。これにより、システムが最新の状態に保たれるだけでなく、リアルタイムのデータ更新によって、その処理を自動化に設定した場合にアクセスできるシステムの精度が上がるため、顧客やクライアントのエクスペリエンスも上がります。
Integrate.io の直感的なインターフェースは、エンドユーザーにとってわかりやすいものであり、データパイプラインを作成するためのドラッグ&ドロップオプションを備えたノーコード環境を採用しています。また、すぐに使える100以上もの内蔵コネクタに加えて、このプラットフォームが対応する多くの一般的な統合機能以外のサービスやデータについても、API の作成と管理が可能です。Integrate.io を利用することで、データウェアハウスがいかにシンプルになるか、こちらから予約できるデモでぜひ覧ください。



