Properly managing storage utilization is critical to performance and optimizing the cost of your Amazon Redshift cluster. We’ve talked before about how important it is to keep an eye on your disk-based queries, and in this post we’ll discuss in more detail the ways in which Amazon Redshift uses the disk when executing queries, and what this means for query performance.
Amazon Redshift uses storage in two ways during query execution:
-
Disk-based Queries. When a query runs out of memory, the overflow “spills” to the disk and the query goes “disk-based”.
-
Intermediate Storage. When a query needs to save the results of an intermediate operation, to use as input for a future operation.
Use excessive storage impacts your cluster because:
- Query performance suffers, because disk is 100 times slower than memory.
- Other queries will be slower, because increased I/O impacts the commit queue which is a shared resource.
- The cluster might hit 100% disk utilization, causing queries to fail or requiring the provisioning of more nodes.
The worst case is (3), when the cluster fills up. It can happen for the all nodes in a cluster at once, or start with just one node, and then propagate through the entire cluster, as the image below shows.

So let’s look into what we can do to fix and prevent this type of situation.
The WLM and Disk-Based queries
If you’re not already familiar with how Redshift allocates memory for queries, you should first read through our article on configuring your WLM.
The gist is that Redshift allows you to set the amount of memory that every query should have available when it runs. This value is defined by allocating a percentage of memory to each WLM queue, which is then split evenly among the number of concurrency slots you define. When a query executes, it is allocated the resulting amount of memory, regardless of whether it needs more (or less). Hence allocating too much memory is wasteful (since each node in the cluster obviously has finite memory), whereas allocating too little memory can cause queries to spill to disk.
Queries which overflow their allocated WLM memory are “disk-based”. These queries usually suffer from significantly degraded performance since disk I/O is orders of magnitude slower than memory I/O.
There are six types of internal operations that Redshift can spill to disk when executing a query:
- Aggregations
- Hashing for joins
- Saving intermediate rows for future query steps
- Sorting
- Removing duplicates from intermediate or final results (unique)
- Window functions
If any of these operations are processing more rows (i.e. more bytes) than will fit into allocated memory, Redshift has to start swapping data out to disk, resulting in a significant slowdown of the query.
AWS recommends that you keep the percentage of disk-based queries to under 10%. On our own fleet of clusters, we’re usually running well under one percent:

How to Prevent Queries From Going Disk-based
- Allocate more memory to the query. There are two approaches to this:
- On the individual query level: Assign more slots to the query by adjusting the session parameter
wlm_slot_count (default is 1).
- At the WLM level: Give more memory to each slot. This can be done by assigning a higher % of memory to the queue (via the AWS Console), or simply reducing the # of slots in the queue (only do this if you have concurrency head-room).
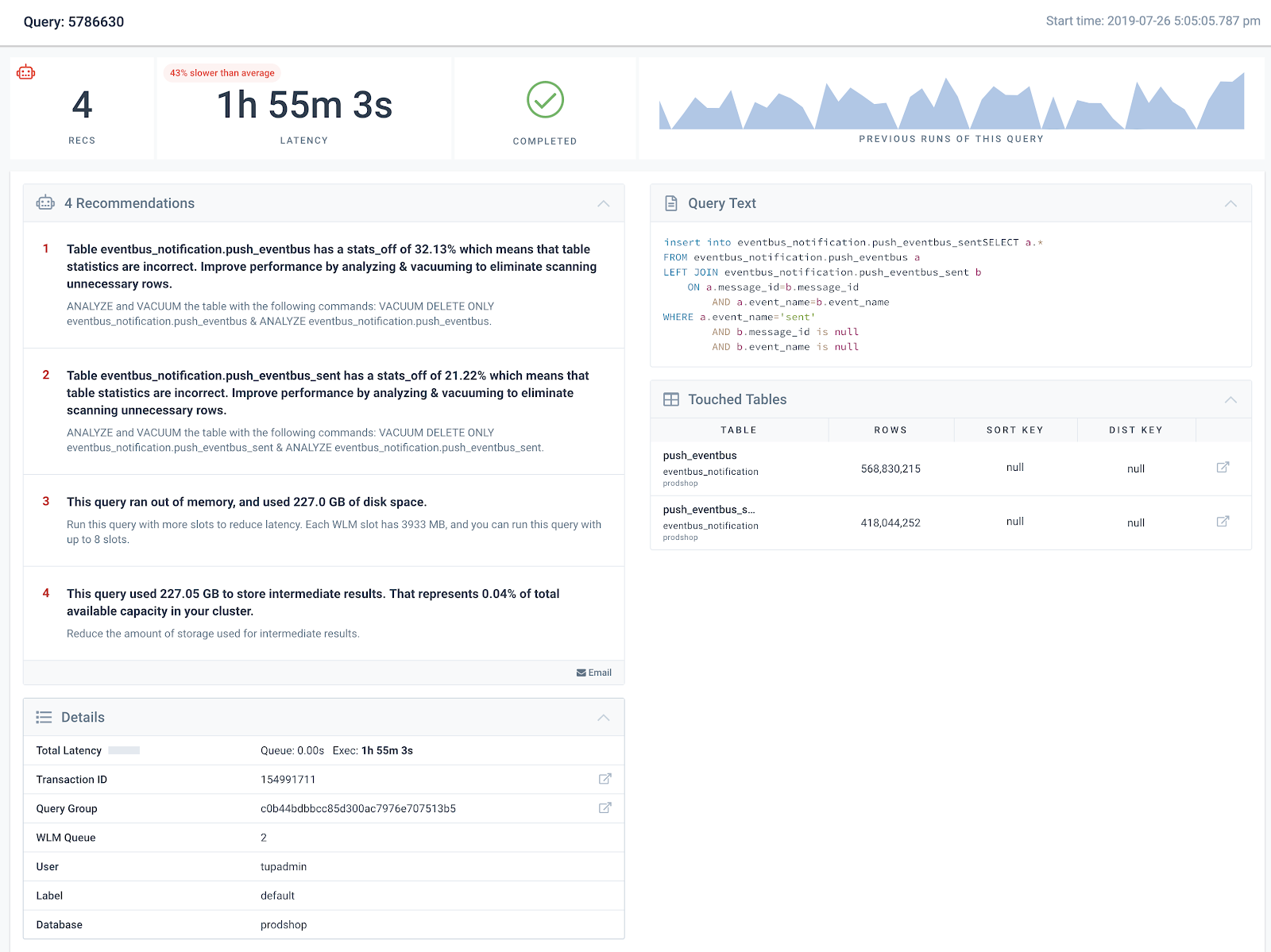
- Ensure touched tables have a low stats-off percentage. This is important to ensure the query planner allocates the correct amount of memory to the query. We discuss this topic in more details in our Top 14 Performance Tuning Techniques for Amazon Redshift article. You can also automate vacuuming and sorting of tables via our Table API.
Within the Integrate.io dashboard, viewing Recommendations for an individual query will surface the exact touched tables and how to update them, as well as how much memory the query used and the amount of memory capacity in the WLM queue.
Intermediate Storage
Redshift also uses the disks in each node for another type of temporary query data called “Intermediate Storage”, which is conceptually unrelated to the temporary storage used when disk-based queries spill over their memory allocation.
Intermediate Storage is used when Redshift saves the results of an intermediate operation to disk to use as input for a future operation. Intermediate Storage can become important if your query stores a large amount of data between query operations, since that storage may cause your cluster to run out of disk space. It also introduces additional I/O, which can lead to slower execution times.
Ways to Limit the Amount of Intermediate Storage Used.
Since intermediate storage is used to carry results from one part of the query execution to another, the best way to reduce intermediate storage is to use predicates (e.g. WHERE clauses, JOIN … ON clauses, etc) on intermediate steps of your query (subqueries, CTEs, etc) to ensure that you are not carrying unnecessary data through your query processing.
For example, consider this query which joins on the results of two CTEs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
with
table1_cte as
(
select * from table1
),
table2_cte as
(
select * from table2
),
select
*
from table1_cte as a
JOIN table2_cte as b
ON a.id = b.id
|
This query could be re-written as follows to limit the amount of data brought forth into the JOIN.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
with
table1_cte as
(
select id,name,address from table1 where id>'{{l_bound}}' and id<'{{u_bound}}'
),
table2_cte as
(
select id,name,address from table1 where id>'{{l_bound}}' and id <'{{u_bound}}'
),
select
a.id, a.name,b.address
from table1_cte as a
JOIN table2_cte as b
ON a.id = b.id
|
We have a great new feature called Query Recommendations that proactively lets you know if your query is using a significant amount of intermediate storage.

Impact to Cluster Storage Utilization
This value is important when diagnosing spikes in cluster storage utilization.
For example, let’s assume you see your cluster storage spiking over some time period, but don’t see a corresponding increase in data transferred (via the COPY command) into your cluster. You could search for all queries which have a large Memory to Disk value to identify which queries contributed to your cluster running out of disk space.
Here’s a real-world example. The following chart shows the actual disk space used in a cluster, over a 2 week period, broken down by schema. This particular chart show consistent storage utilization over time, with small variation.

The chart of % disk utilization tells a different story. On the same cluster, over the same period, the disk utilization hits 100% quite frequently. This is caused by some queries using an extraordinary amount of intermediate storage.

One of the cool features we recently released Cluster Recommendations, will surface queries with high disk utilization immediately. For this cluster, it appears that queries were using close to two terabytes of disk for intermediate results!

Conclusion
Monitoring both “Disk-based Queries” and “Intermediate Storage” is crucial to keeping your cluster healthy. Keeping on top of this temporary disk utilization prevents your Amazon Redshift disks from filling up due to misbehaved queries, resulting in queries being killed and your users being interrupted.