Creating a service account for FlyData to use requires the BigQuery Data Editor role.
- Go to your project's service accounts page and click
+ CREATE SERVICE ACCOUNT.
- Enter the
Service account name and add a description.
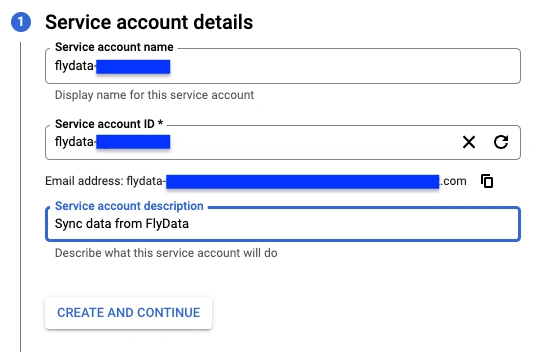
Click CREATE AND CONTINUE.
- Select the
BigQuery Data Editor role.
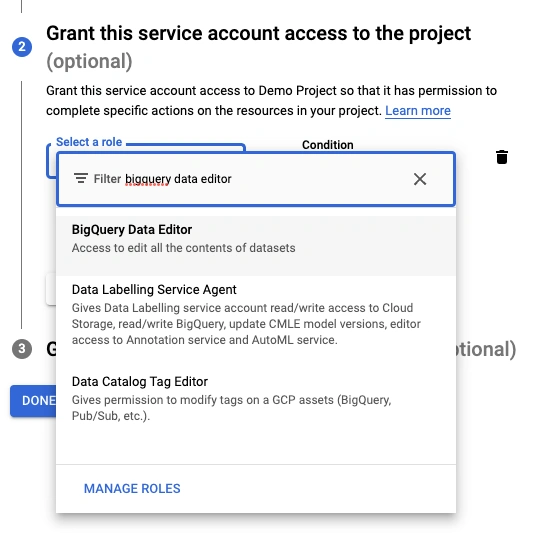
- Select the
BigQuery Job User role.
Click CONTINUE.
- Click
DONE.
- The service account should have been created successfully. Find it in the service accounts list and click it.

- Go to the
KEYS tab.
- Click
ADD KEY and select CREATE NEW KEY.
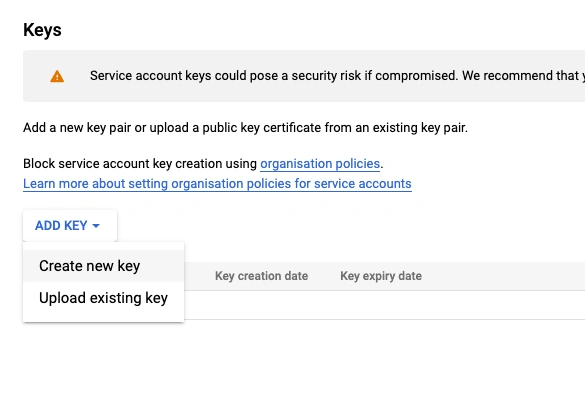
- Select
JSON and click CREATE.

- A JSON file should have been downloaded to your system. Upload it.
We will fetch the client_email and private_key properties from the JSON credential file.
Limitations
BigQuery doesn’t support deduplication. Instead, the following columns are added to the destination table for future deduplication on the customer’s side.
__offset - Offset column. Keeps track of the offset in incremental order to determine which existing row is the latest.
__op - Operation column. Tells what kind of operation is performed for a particular row (0 - Created, 1 - Inserted, 2 - Updated, 3 - Deleted)
This query is to list the de-duplicated records:
SELECT customer.*
FROM (SELECT id,
ARRAY_AGG(
t ORDER BY t.__offset DESC LIMIT 1
)[OFFSET(0)] customer
FROM `euphoric-effect-296205.northwind.customer` t
GROUP BY id);
This query is to upsert a staging table that Integrate.io is syncing to, into a production table used for querying:
MERGE INTO `northwind`.customers o
USING (SELECT event.*
FROM (SELECT customer_id,
ARRAY_AGG(
t ORDER BY t.__offset DESC LIMIT 1
)[OFFSET(0)] event
FROM customers_staging_1 t
GROUP BY customer_id)) as s
ON o.customer_id = s.customer_id
WHEN MATCHED AND s.__op = 3 THEN
DELETE
WHEN MATCHED THEN
UPDATE SET o.company_name = s.company_name, o.__op = s.__op
WHEN NOT MATCHED THEN
INSERT ROW
After deleting tables on BigQuery, we have to wait (5+ minutes) to let the change propagate to all the machines in the BigQuery cluster. Otherwise, it might lead to some rows missing. This happens on resync requests. Please contact support@integrate.io to assist with the resync timing of user tables.