Connection Setup
In Redshift console
1
Start by navigating to the Redshift console —> Clusters screen and clicking on the Properties tab.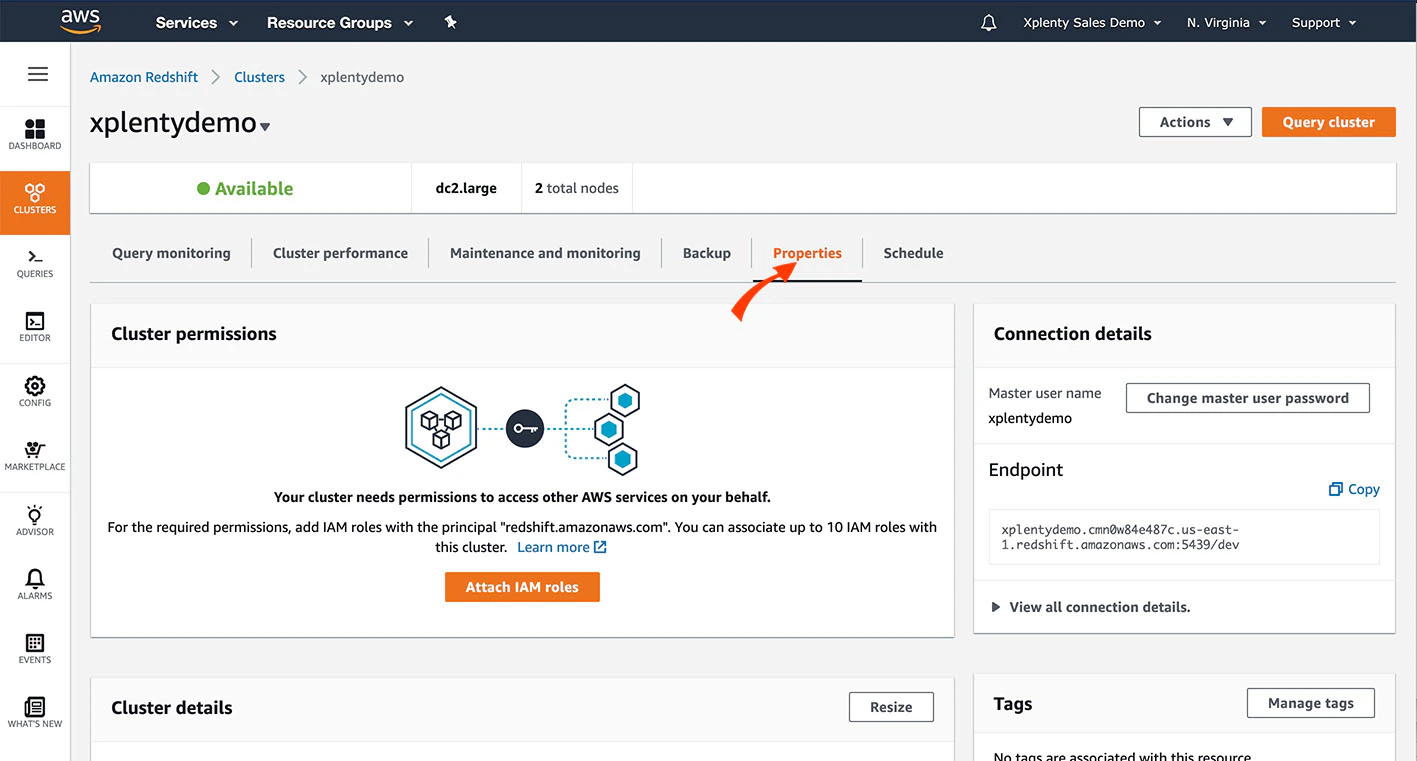
2
Scroll down to the Network and Security section. Make sure that the cluster is set with the value for Publicly Accessible to Yes. Then, click the VPC Security Group to verify and/or modify the security rules.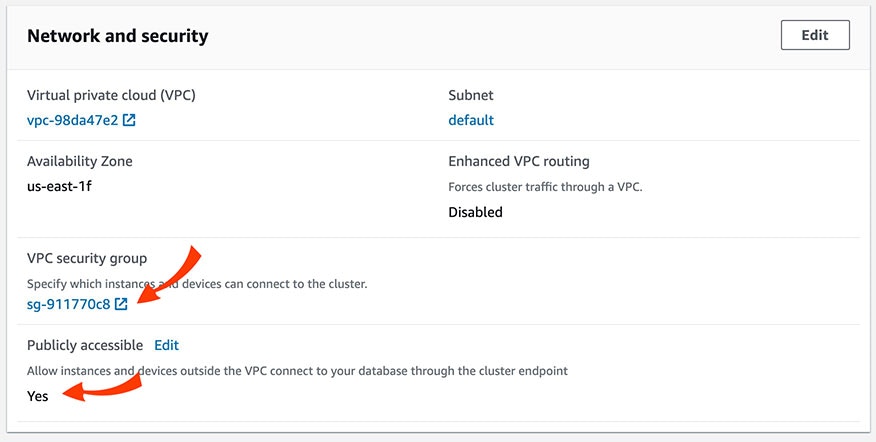
3
In the Security Group screen, select the Inbound tab.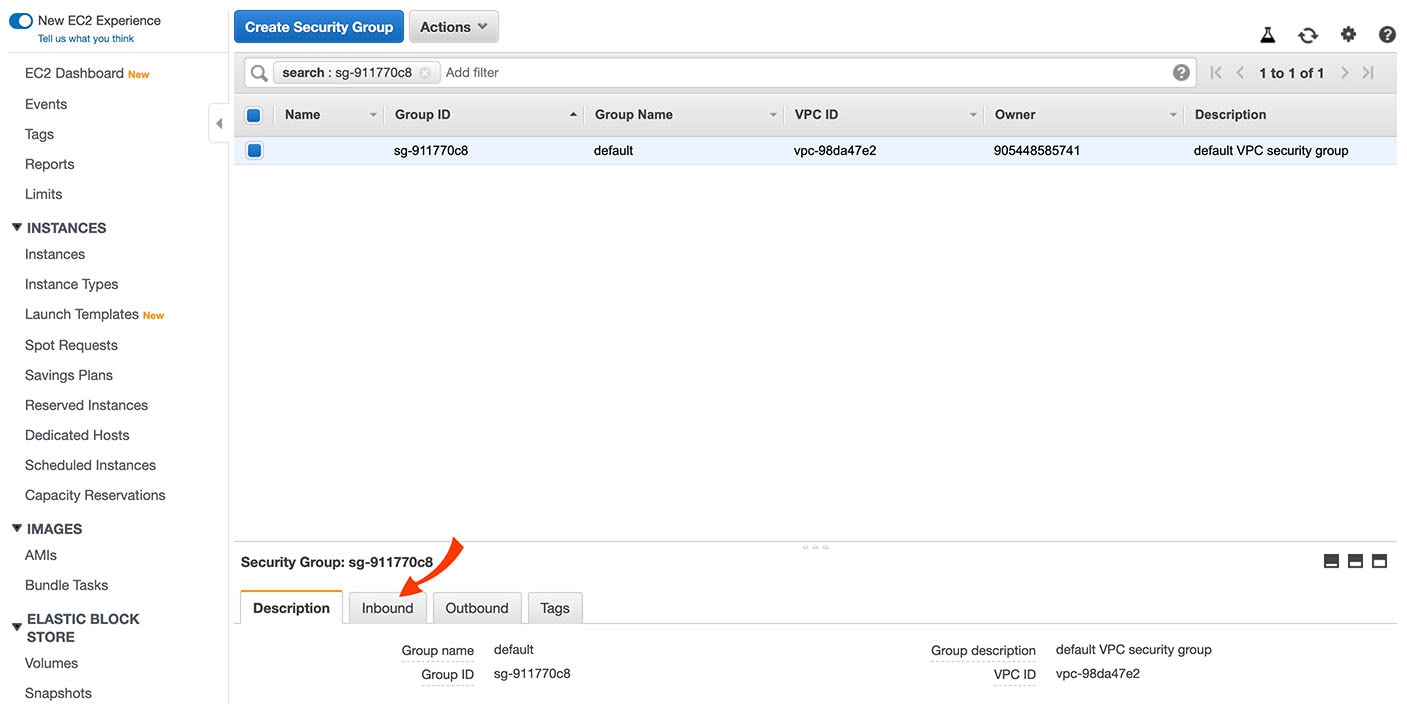
4
There should be rules for the IP addresses listed here. If those rules need to be altered or don’t exist, click Edit.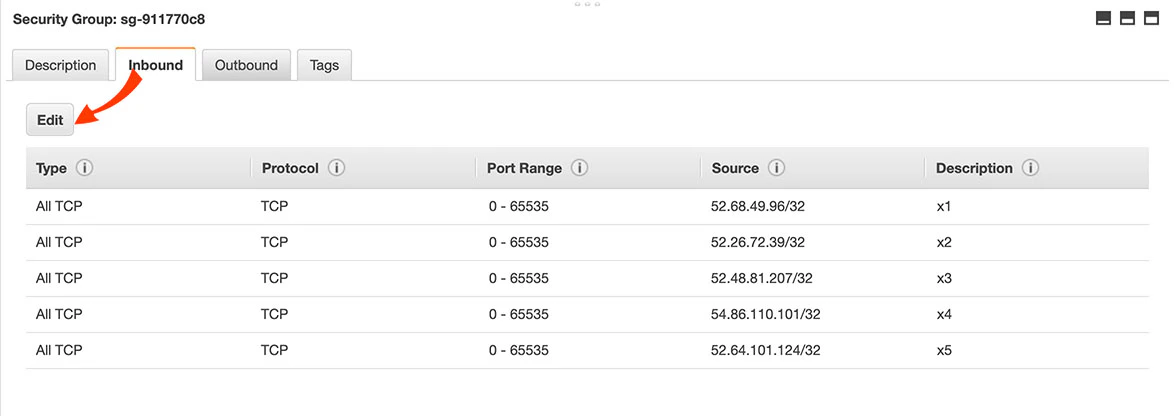
5
Edit any existing rules or click Add Rule to add a new rule. For each rule, select the type of database and enter the Redshift port. Then click Save.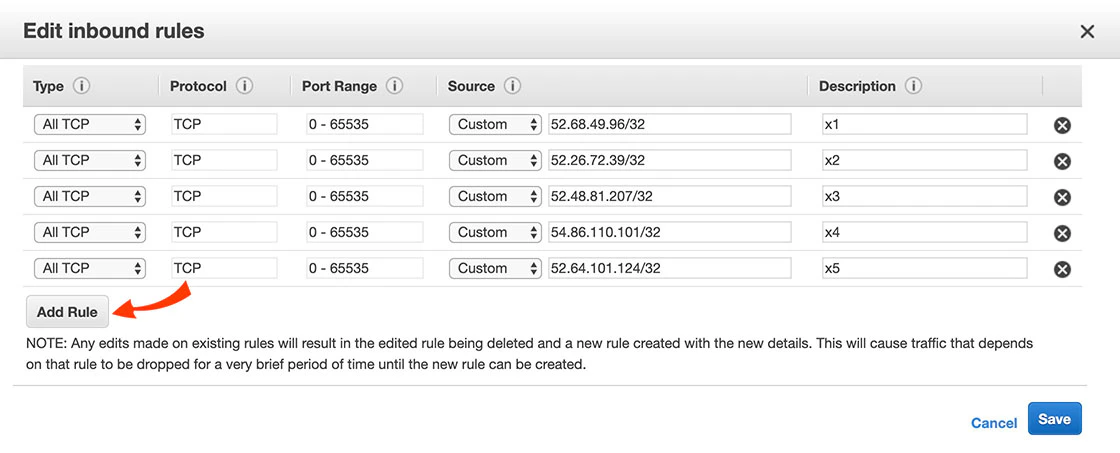
To verify or modify the security rules of an instance on EC2-Classic (without VPC)
In your Redshift Cluster Security Group, modify a rule or add a new rule for each IP address listed here: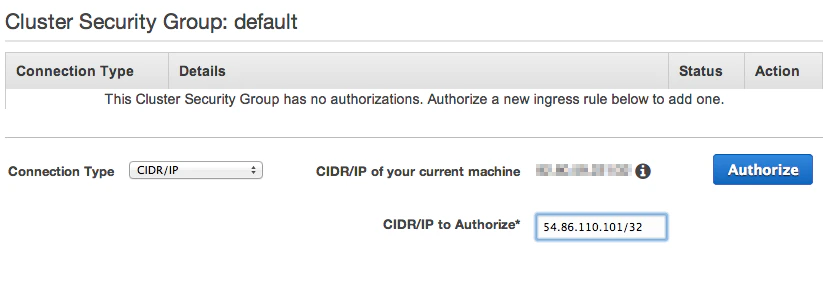
- In the Connection Type dropbox, choose CIDR/IP.
- In the CIDR/IP to Authorize field, enter the IP addresses from this list.
Create a Redshift user
- Create a Redshift user.
- Grant it the following permissions:
- If you intend to only append data into a table, give the user minimal permissions required to execute the COPY command.
- If you intend to merge data into a table, give the user minimal permissions required to execute the COPY command, create a table, and insert and update to your target tables.
- Note that truncate requires Integrate.io ETL to either be the owner of the target table or have superuser access.
To define a connection in Integrate.io ETL to Amazon Redshift
1
Click Connections (the lightning bolt) on the left side of the dashboard.
2
Click New connection.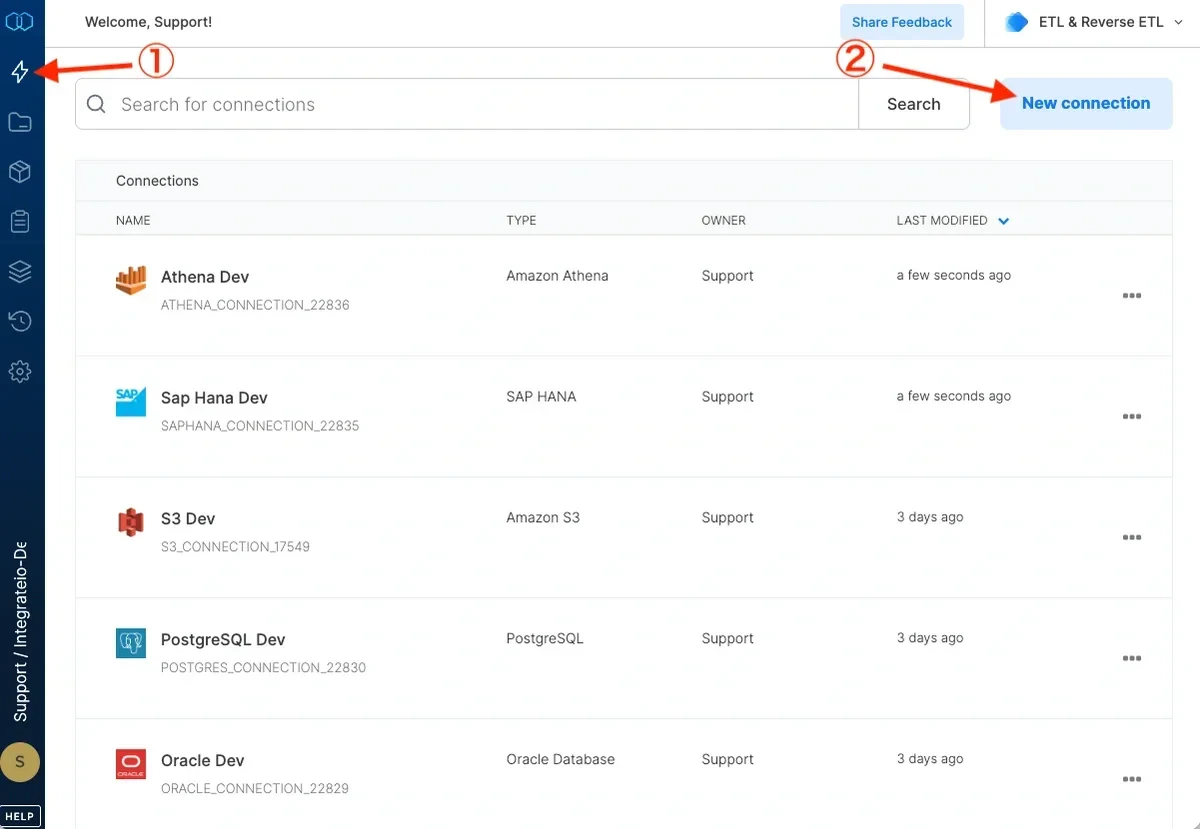
3
Select Amazon Redshift from the Analytical Database category.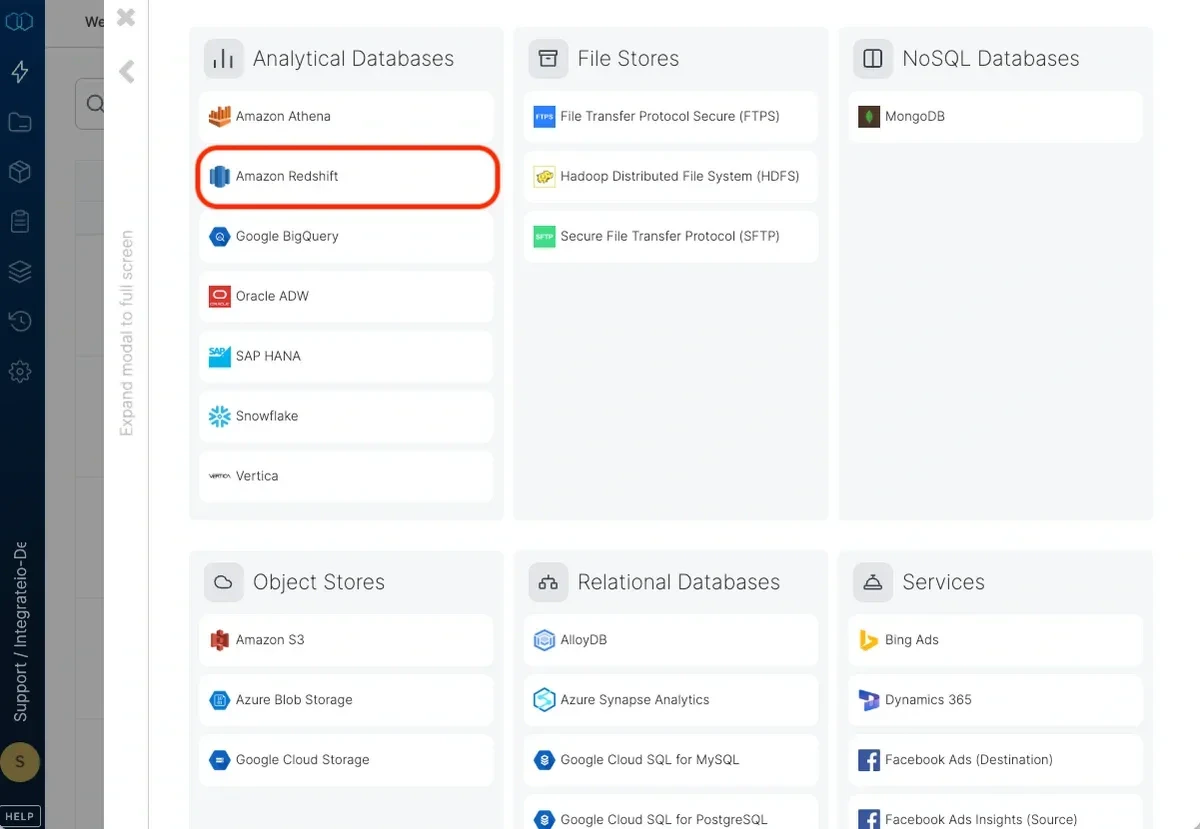
4
Type a name for the connection.
5
If you allow direct access from Integrate.io ETL’s IP addresses, enter the hostname and port. If direct access is not allowed, read more about setting a tunnel connection here.
6
Enter the user name and password you created for Integrate.io ETL to use.
7
Enter the default database to use. If you leave it empty, the user’s default database will be used.
8
Set the region to the AWS region in which the Redshift cluster was created. If the region requires AWS Signature v4 (see list here) you may need our support team’s help with allowing Integrate.io ETL access to read from this Amazon Redshift connection.
9
Click Test connection. If the credentials are correct, a message that the cloud storage connection test was successful appears.
10
Click Create connection and the connection is created and appears in the list of connections.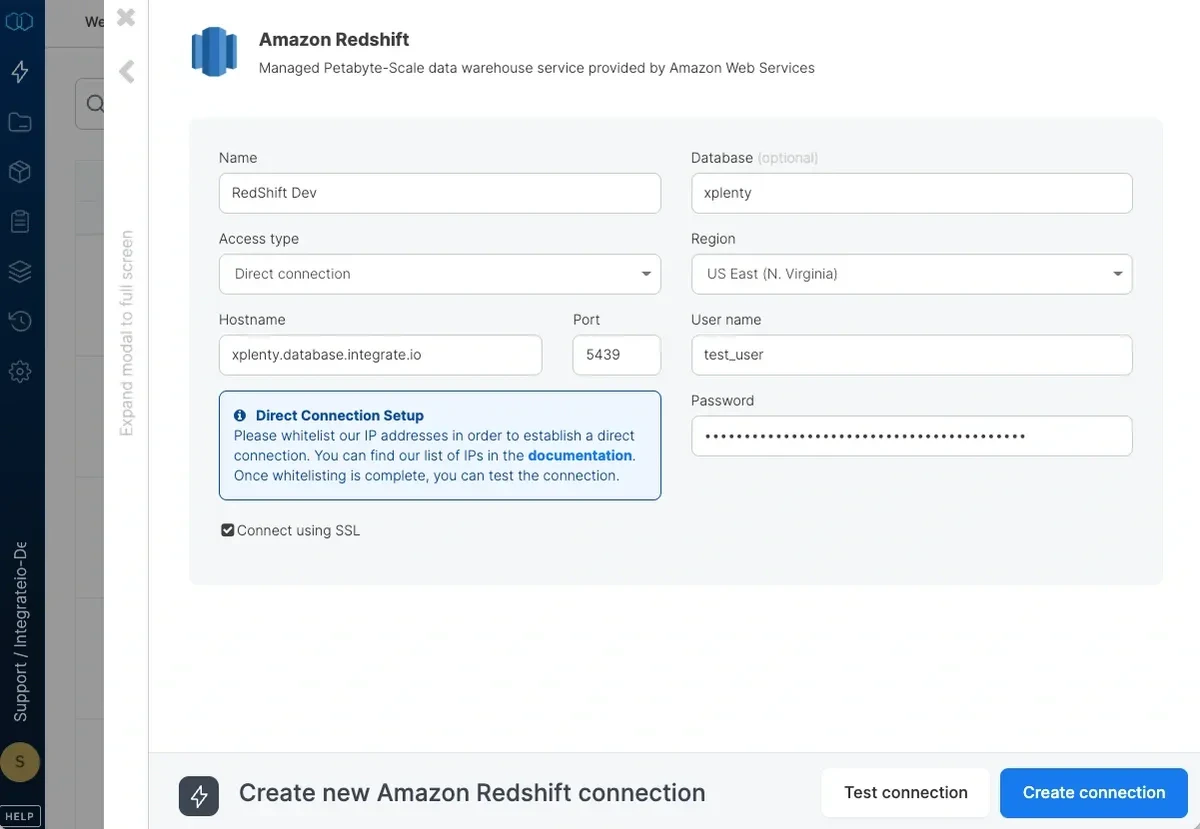
Connection
Select an existing Amazon Redshift connection or create a new one (for more information, see Allowing Integrate.io ETL access to my Redshift cluster.)Source Properties
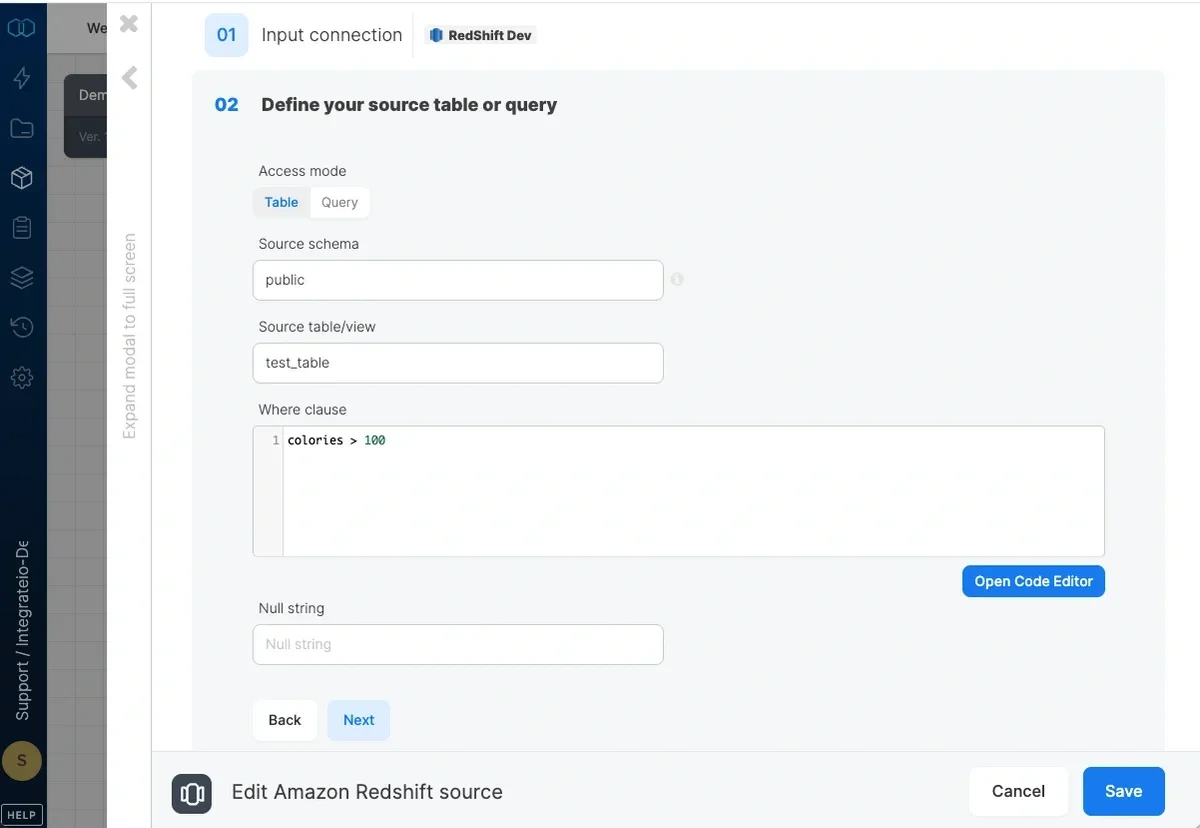
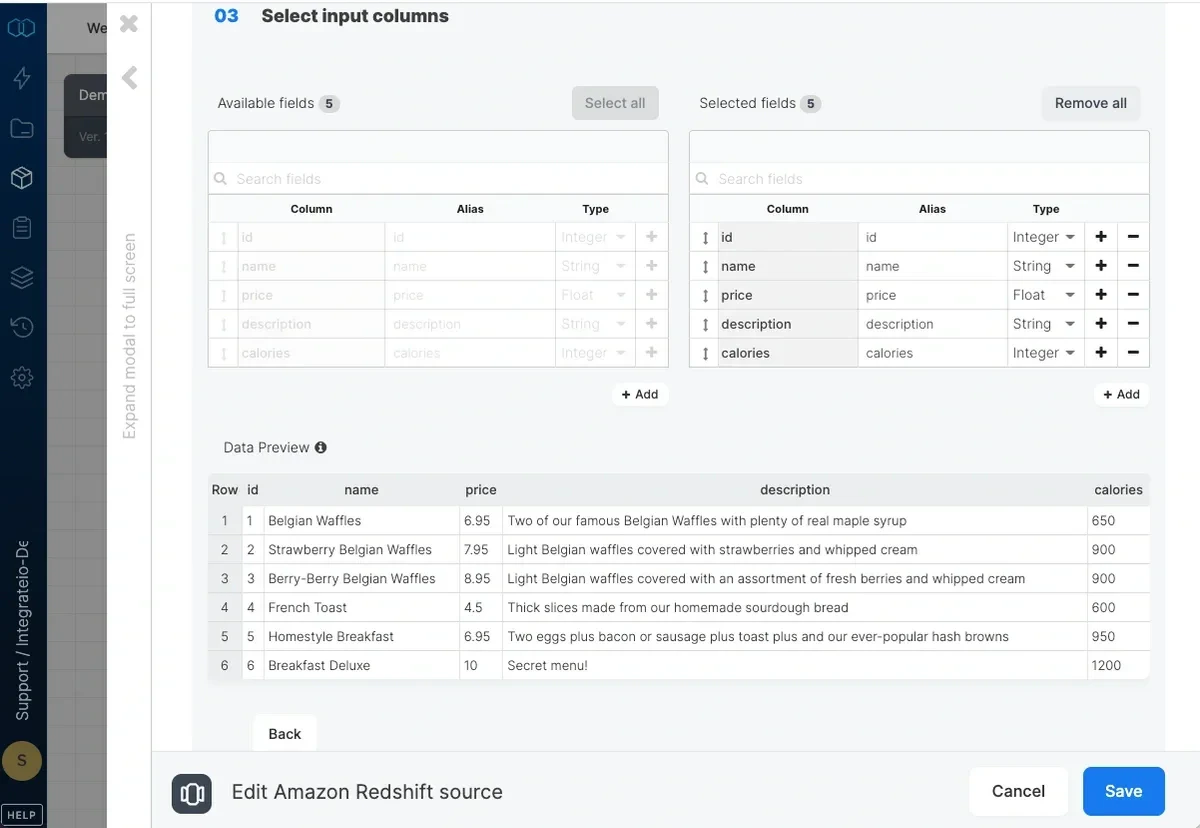
- Access mode - select table to extract an entire table/view or query to execute a query.
- Source schema - the source table’s schema. If empty, the default schema is used.
- Source table/view - the table or view name from which the data will be imported.
- where clause - optional. You can add predicates clauses to the WHERE clause as part of the SQL query that is built in order to get the data from the database. Make sure to skip the keyword WHERE.
- Query - type in a SQL query. Make sure to name all columns uniquely.
- Null string - NULL values in string columns will be replaced with the string specified here. By default NULL values will appear like empty strings.
Source Schema