Connection
Select an existing MongoDB connection or create a new one (for more information, see Allowing Integrate.io ETL access to MongoDB.)Destination Properties
- Target collection - The name of the target table in your database. If the table doesn’t exist, it will be created automatically.
- Operation type - The method of data insertion.
- Insert only (Append) - Default behavior. Data will only be appended to the target table.
- Merge with existing data using update and insert - Incoming data is merged with existing data in the table by updating existing data and inserting new data. Requires setting the merge keys correctly in field mapping. In case of multiple document match in destination, it will only update a single document.
- Insert only (Append) - Default behavior. Data will only be appended to the target table.
Schema Mapping
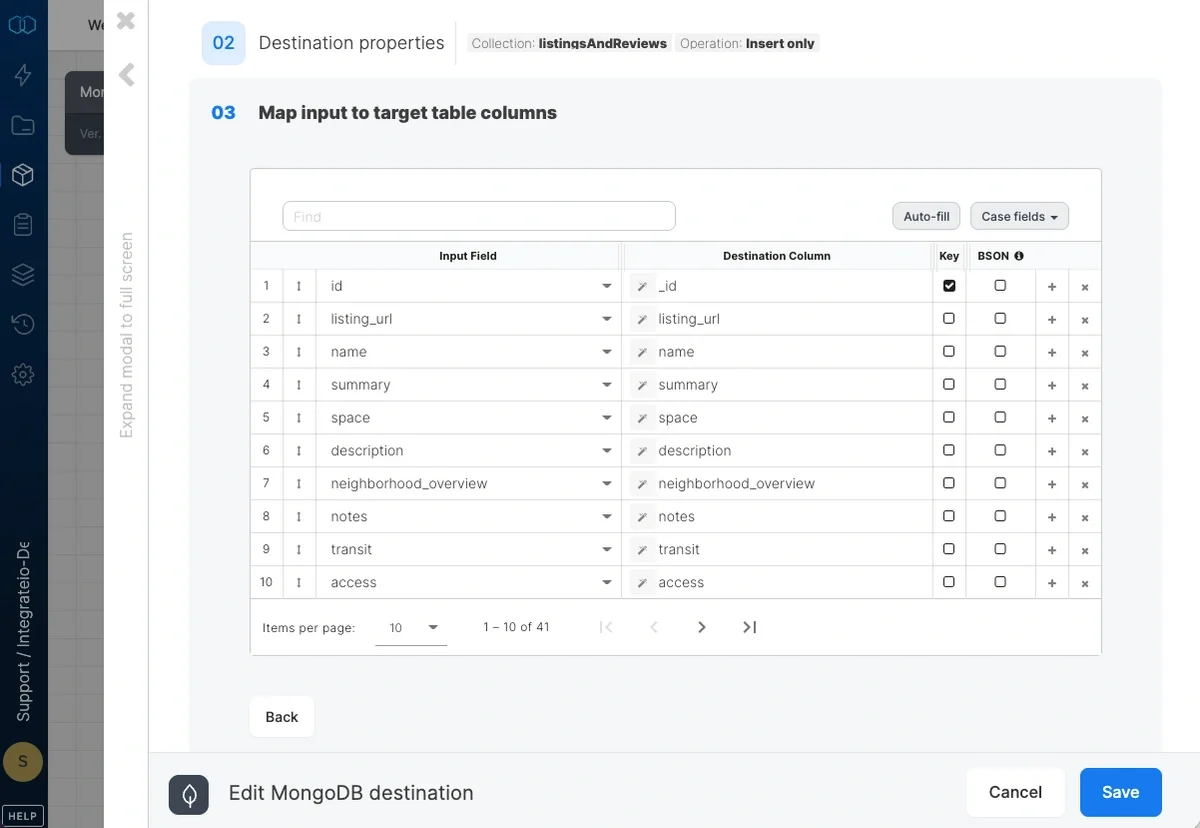
- If merge operation is used, check the Key checkbox on one or more fields to specify the merge key.
- Check the BSON checkbox on fields that are Bag / Map data types. This is so that Integrate.io ETL can ingest them as MongoDB array or object accordingly.
| Integrate.io ETL | MongoDB |
|---|---|
| String | String |
| Integer | 32 Bit Integer |
| Long | 64 Bit Integer |
| Double | Double |
| Boolean | Boolean |
| Bag | Array |
| Map | Object |
How to Set a Primary Key
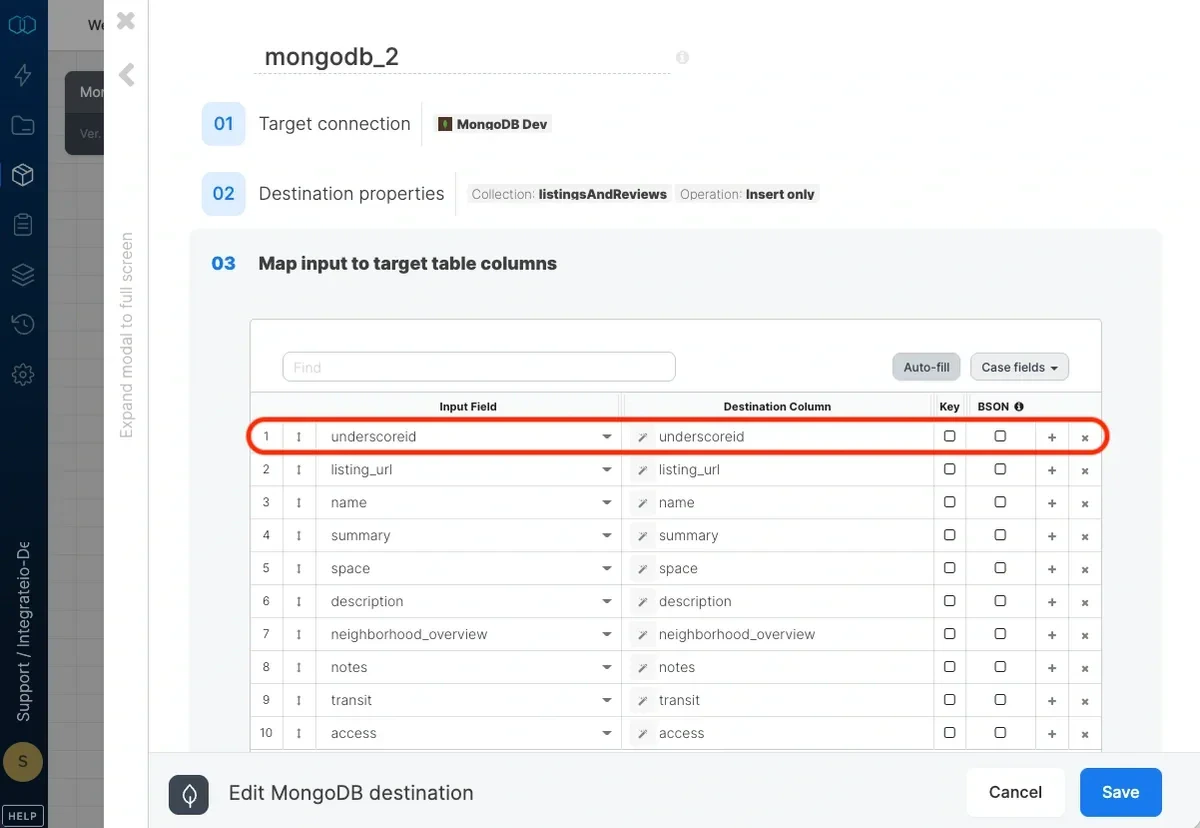
The _id field is a unique column that MongoDB uses across all of its rows. It is the primary key on all elements in a collection and it’s automatically indexed. To specify custom _id values on your dataset, you can use the alias “underscoreid” on the column that you would like to use as _id. Integrate.io ETL would automatically detect this as _id.