

< integrate.io의 블로그 기사 번역 >
로우코드 및 노코드 기능을 갖춘 Integrate.io는 모든 기업의 ETL과 데이터 통합을 지원합니다. 그러나 Integrate.io의 매우 사용자 친화적인 인터페이스임에도 의도한 변환이 예상대로 작동하지 않을 수 있기에 문제를 신속하게 디버깅하고 해결해야 합니다. 다행히 Integrate.io에는 문제를 해결하기 위한 여러 디버깅 옵션이 있습니다. 다음은 Integrate.io에서 디버깅할 수 있는 세 가지 방법을 설명합니다. 여기에는 ETL 파이프라인을 통과할 때 데이터를 시각화할 수 있는 새로운 기능인 컴포넌트 프리뷰어도 포함되어 있습니다. **디버깅 방법 **1 : 파일 스토리지에 쓰기 Integrate.io에서 가장 쉬운 디버깅 방법 중에 하나가 중간 데이터를 S3와 같은 파일 저장소에 쓰고, 그 파일을 열어 데이터 출력 결과를 이용하여 오류를 검사하는 것입니다. Integrate.io에는 Clone 컴포넌트(처리를 분기하는 기능)가 있어 하나의 데이터 흐름을 두 개 이상의 데이터 흐름으로 나눌 수 있습니다. Integrate.io에서 디버깅하기 위해 ETL 파이프라인에 Clone 컴포넌트를 삽입할 수 있습니다. 한쪽 데이터 흐름은 그대로 원래의 파이프라인으로 보내고, 다른 한쪽 데이터 흐름은 중간 출력을 파일 스토리지 버킷(예: Amazon S3)으로 출력합니다. 파일 스토리지는 데이터의 포맷에 관계없이, (버그가 있어도) 문제없이 출력 할 수 있습니다. 또 다른 이점은 파일 저장소에 쓰면 출력 결과를 한눈에 볼 수 있으므로 일부 데이터에 작은 오류가 숨겨져 있을 때도 매우 유용합니다. 다음은 지금까지 설명한 디버그 처리를 실제로 파이프라인에 구현한 경우 Integrate.io 대시보드에서 어떻게 보이는지를 보여주는 간단한 예입니다. 디버그 플로우를 추가하기 전에 select_1 및 select_3 컴포넌트는 직접 연결되었습니다. clone_2 컴포넌트는 데이터 흐름을 두 개로 나눕니다. 한쪽 데이터 흐름은 select_3 컴포넌트에 연결되고 다른 한쪽 데이터 흐름은 file_storage_4 컴포넌트로 출력됩니다. [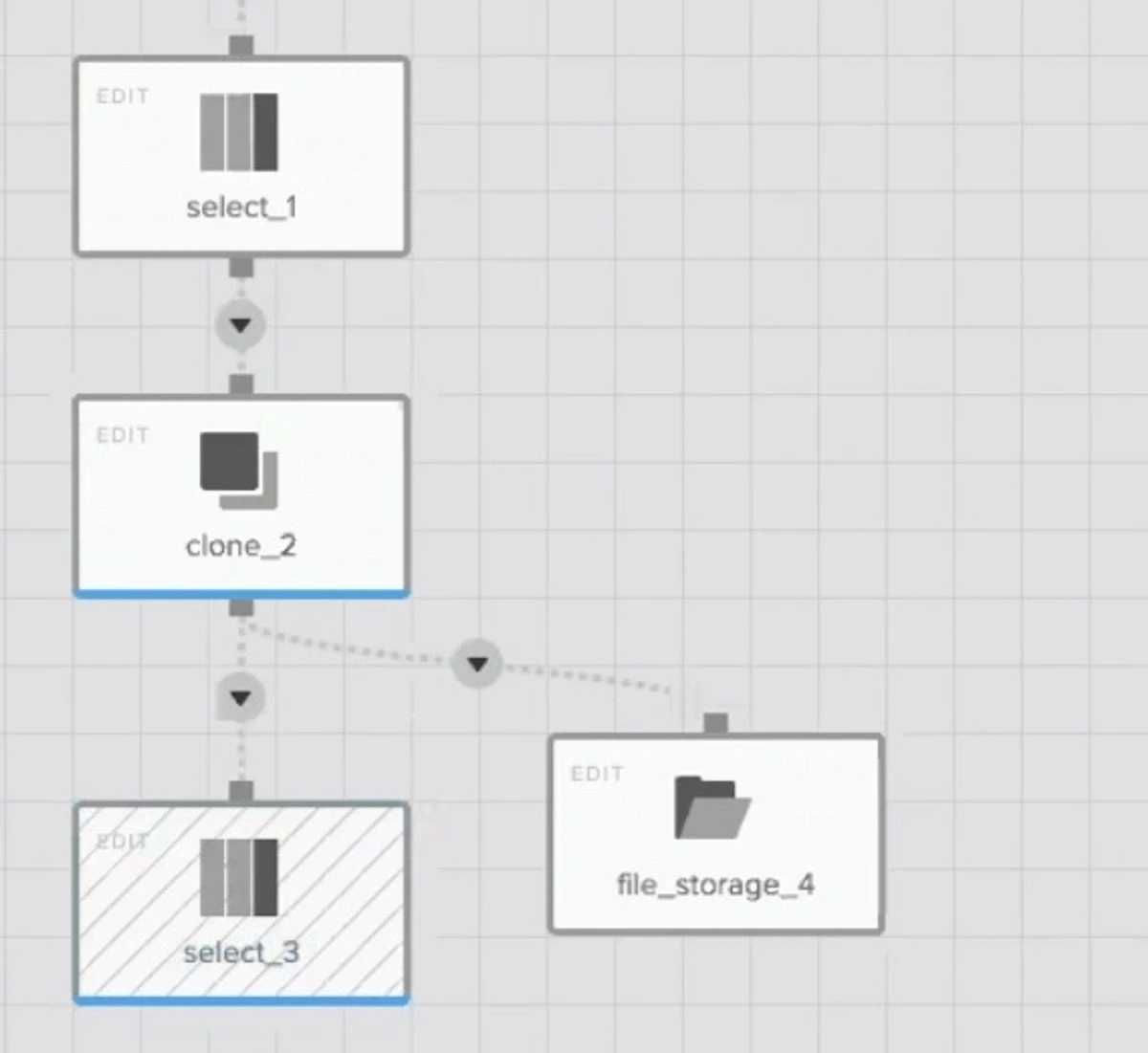
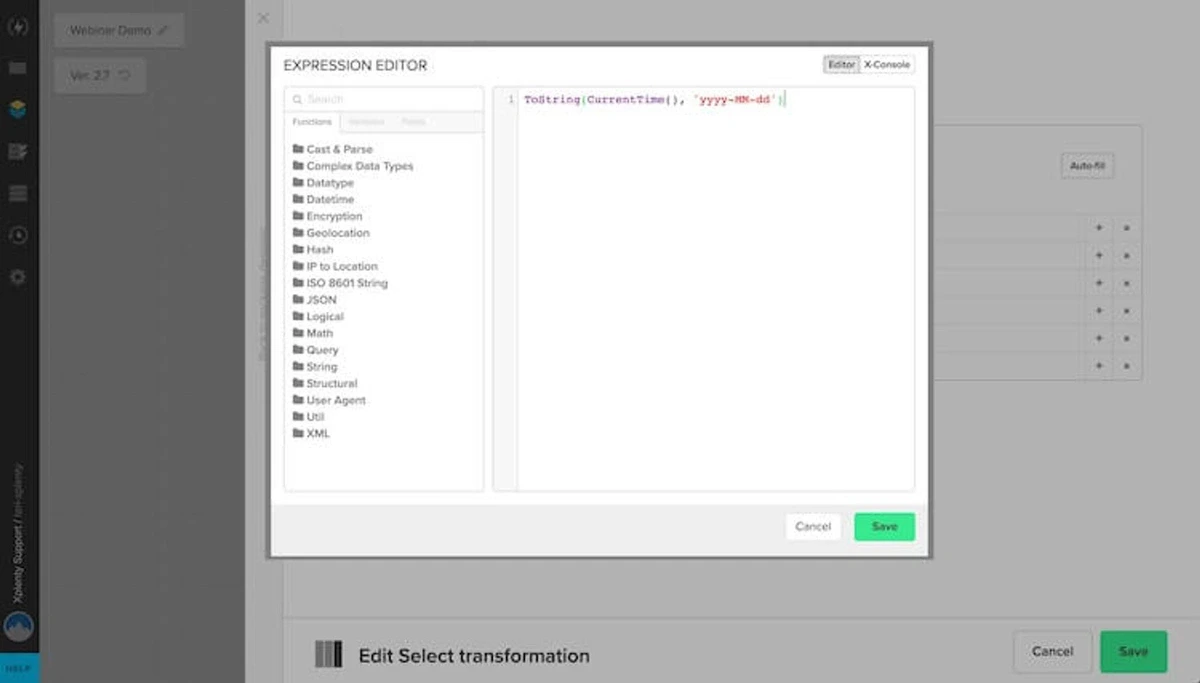
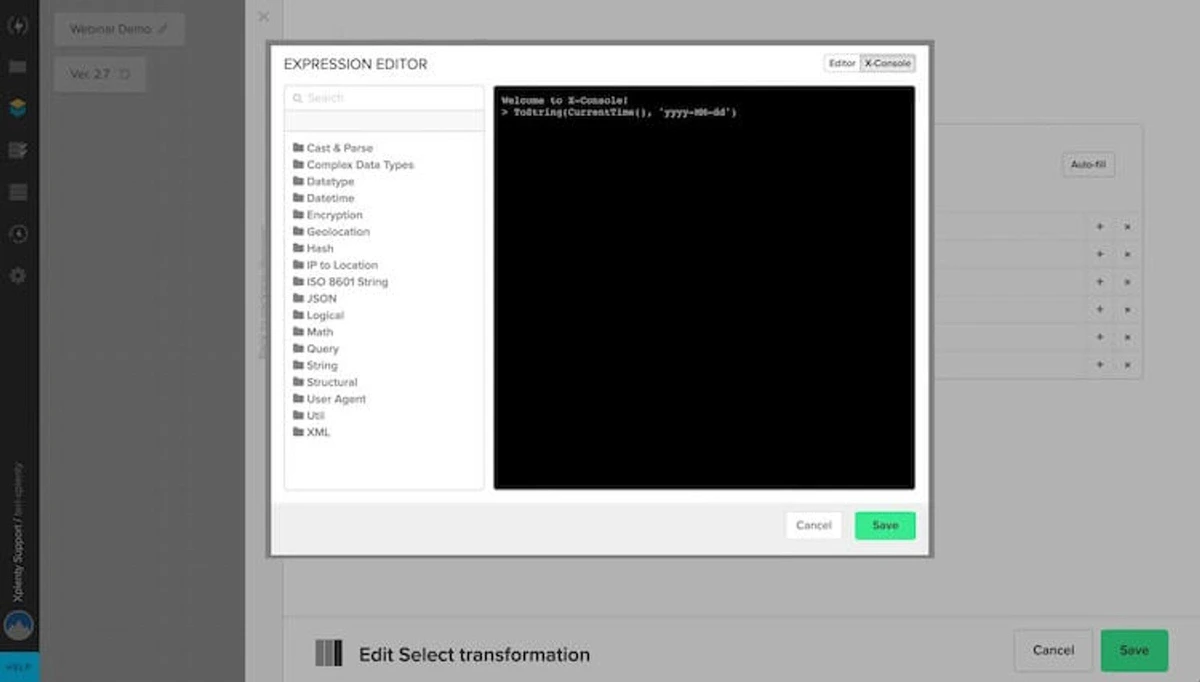
- 파일 스토리지에 쓰기는 많은 양의 데이터를 처리하기에는 복잡하고 번거로울 수 있습니다.
- X-Console은 작업을 실행할 때 사용할 데이터를 조작할 수 없으며 콘솔에서 정의한 변수만 조작할 수 있습니다.
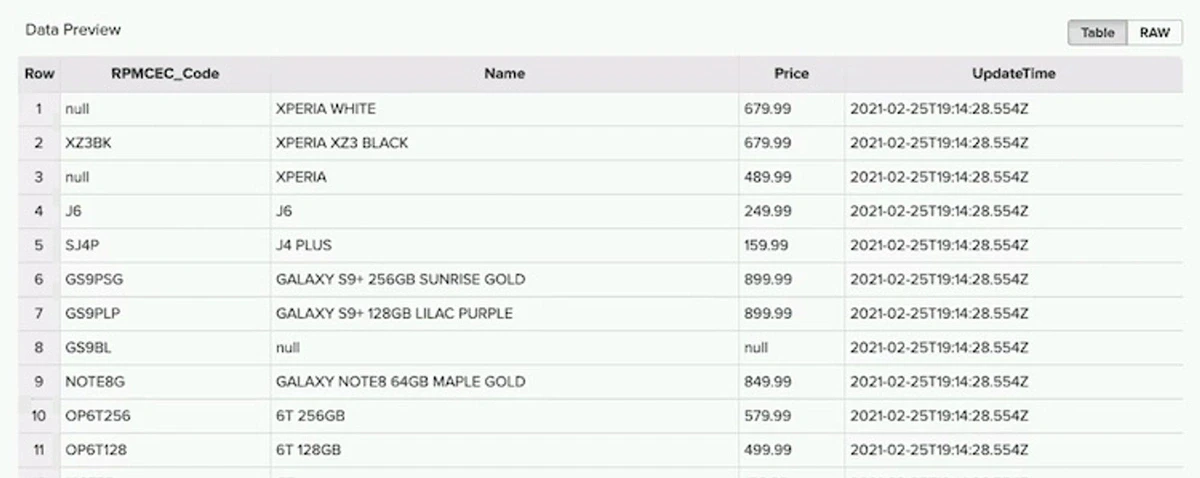
- 상단의 검색창에 status:failed를 입력하고 Search 버튼을 클릭합니다.
- 오류가 발생한 작업이 새 작업에서 이전 작업 순서로 목록에 표시됩니다. 해당 작업의 오른쪽에 있는 View details를 클릭합니다. 그러면 해당 작업의 오류 로그가 포함된 Windows가 표시됩니다. 디버깅하려는 오류의 로그를 확인합니다.
