들어가며 FileStorage 소스와 데스티네이션은 Xplenty에서 가장 많이 사용되는 컴포넌트입니다. 특히 다양한 포맷을 지원하며, 서로 다른 시스템 간의 데이터 연계에 필수적인 존재이기도 합니다. 2024년 초부터는 Parquet 형식의 쓰기 뿐만 아니라 읽기까지 지원하게 되었습니다. 이번 글에서는 Xplenty에서 Parquet으로 쓰기를 설정하는 방법을 소개하고자 합니다. Parquet 형식의 장단점 이미 많은 고객님들이 알고 계시겠지만, Parquet 형식에 대해 조금 정리해 보겠습니다. Parquet 형식의 정식 명칭은 Apache Parquet이며, 대량의 데이터를 효율적으로 저장하면서 비교적 높은 읽기 성능을 제공하기 위해 개발된 데이터 저장 형식입니다. 주요 장점은 아래와 같으며, 요약하자면 대용량 데이터를 다루기 쉬워 분석 업무에 적합하다는 점과 디스크 용량을 줄여주는 압축 사양 임에도 불구하고 로딩이 빠르다는 점을 꼽을 수 있습니다. 장점 설명 컬럼 지향 데이터 포맷으로 대용량 데이터 처리 가능 Parquet은 컬럼 지향 포맷으로 데이터를 저장하기 때문에 쿼리에서 필요한 컬럼만 읽을 수 있습니다. 따라서 데이터 양이 많은 경우에도 성능이 향상됩니다. 효율적인 압축으로 디스크 사용량 대폭 절감 Parquet은 데이터를 압축하여 저장하기 때문에 디스크 사용량을 줄여줍니다. 특히 수치 데이터나 반복이 많은 데이터에 대해 높은 압축률을 발휘합니다. 빠른 쿼리 처리 데이터가 컬럼 단위로 저장되기 때문에 특정 컬럼에 접근하는 쿼리는 매우 빠르다. 예를 들어, 분석용 쿼리에서 특정 필드에만 접근하는 경우, 전체 행을 읽어들일 필요가 없기 때문에 처리 효율이 높아진다. 스키마가 있어 데이터 공유가 용이 Parquet은 스키마(데이터 구조)를 지원하기 때문에 데이터 로딩 시 스키마의 정합성을 확인할 수 있다. 이를 통해 서로 다른 애플리케이션 간 데이터 공유가 용이해집니다. 대용량 데이터 분석에 적합 대규모 데이터 세트를 효율적으로 처리하기 때문에 Hadoop, Spark, Hive 등의 분석 도구와 궁합이 잘 맞아 대량의 데이터를 다루는 빅데이터 처리에 적합하다. 하지만 세상 모든 것이 장단점이 있듯이 Parquet 형식은 아래와 같은 단점도 있다. 단점 설명 작은 데이터 세트의 경우 다른 데이터 형식이 더 효율적 Parquet은 대규모 데이터 세트의 성능에 최적화되어 있기 때문에 작은 데이터나 실시간 처리에는 적합하지 않습니다. 작은 데이터 세트의 경우, JSON이나 CSV와 같은 행 지향 형식이 더 효율적일 수 있습니다. 높은 쓰기 비용으로 업데이트 빈도가 높은 작업에는 적합하지 않음 Parquet은 압축과 컬럼 단위의 데이터 저장으로 인해 쓰기 시 오버헤드가 상대적으로 높습니다. 특히 데이터 추가 및 업데이트 빈도가 높을 경우 성능이 저하될 수 있다. 스키마 유연성이 낮기 때문에 스키마 변경에 주의해야 한다 Parquet은 엄격한 스키마를 가지고 있기 때문에 스키마가 자주 바뀌는 데이터에는 적합하지 않다. 스키마 변경이 필요한 경우, 전체 데이터를 다시 작성해야 할 수도 있습니다. 지원되는 생태계의 제약 Parquet은 빅데이터 처리를 위한 도구(Hadoop, Spark 등)와 매우 잘 어울리지만, 소규모 데이터 처리나 일반적인 애플리케이션에는 적합하지 않을 수 있다. 이처럼 Parquet 형식으로 저장된 데이터는 대규모 데이터의 효율적인 쿼리 처리 및 압축에 매우 적합하며, 특히 빅데이터 및 분석 용도에서 높은 성능을 발휘한다. 이런 점에서 Parquet 형식은 대용량 데이터 전송을 전문으로 하는 Xplenty와도 궁합이 잘 맞는 형식이라고 할 수 있다. Xplenty에서 Parquet 포맷으로 쓰기 Parquet 포맷에 대한 쓰기 기능은 이전부터 제공되어 왔으며, 아래에서 설명할 데모용 패키지는 Xplenty을 통해 대량의 CSV 파일을 Parquet 포맷으로 작성해 보도록 하겠습니다.Documentation Index
Fetch the complete documentation index at: https://www.integrate.io/docs/llms.txt
Use this file to discover all available pages before exploring further.
1. 대량의 CSV 데이터 준비
Parquet 형식을 이용해 보기 위해서는 대량의 데이터가 필요하다. 이번에는 미국 citibike사의 운행 데이터를 사용할 예정인데, 1년간의 운행 데이터는 압축해도 1기가를 훌쩍 넘기 때문에 parquet 형식 테스트에 적합하고 누구나 사용할 수 있도록 공개되어 있다. 그 중에서 선택한 것은 2020년도 citibike-운행 데이터로 zip으로 압축한 용량이 751.2메가인 단일 파일이다. 얼핏 용량이 작아 보이지만 압축을 풀면 무려 총 합이 3.61기가인 27개의 거대한 CSV 파일군으로, zip의 압축률을 환산하면 약 21%의 압축률입니다. 이번 쓰기 데모에서는 Parquet 형식의 쓰기가 일반 텍스트 CSV에 비해 어느 정도의 압축 효율을 보이는지 살펴보겠습니다. 먼저, 서두에 소개한 링크에서 운행 데이터를 다운로드하고, 로컬에서 압축을 푼 후에 나온 csv 파일들을 아래 그림과 같이 S3나 FTP 서버에 저장한다. [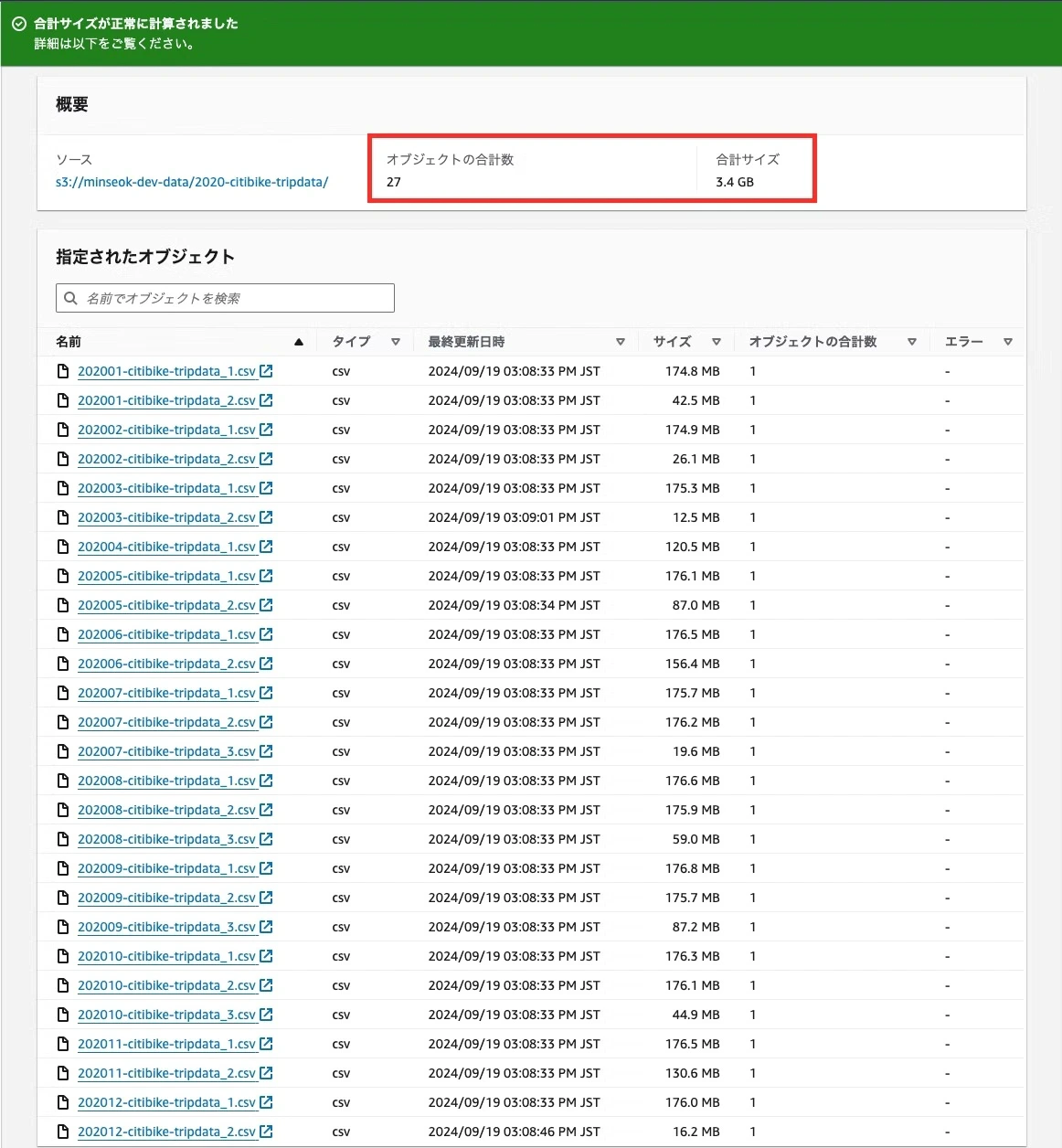
2. CSV 파일 불러오기
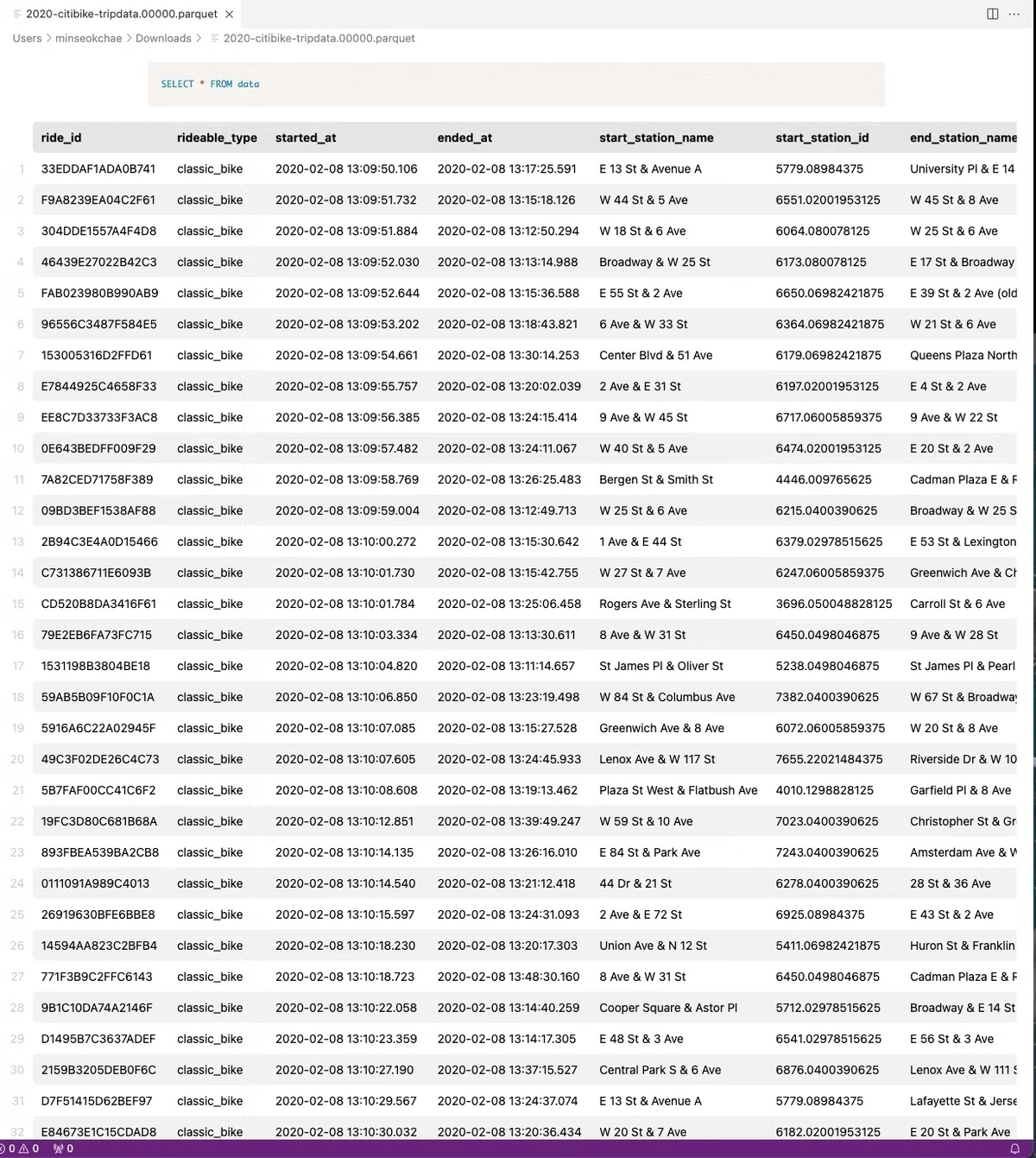
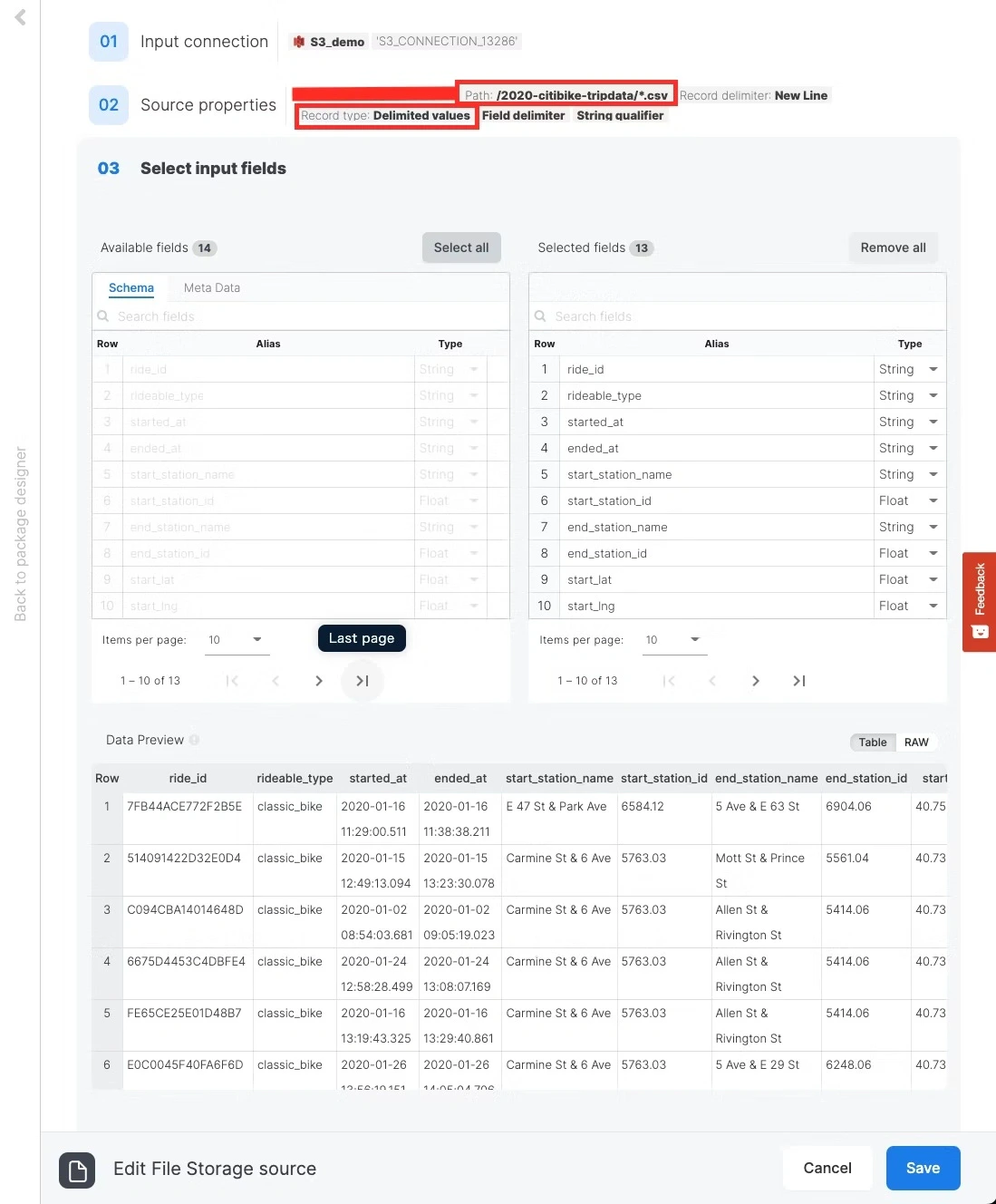
Xplenty의 패키지 편집 화면에서 FileStorage source를 넣고 아래와 같이 상세 설정을 한 후, 모든 필드를 선택하면 아래 그림과 같이 Data Preview에서 데이터 불러오기를 확인할 수 있습니다. 항목명 설정값 Connector S3 Bucket 해당 커넥터의 버킷 이름 Path/2022-citibike-tridata/*.csv
Record delimiter
New Line
Record type
Delimiter values(CSVファイルを意味)
Delimiter
,
String qualifier
"
Escape character
\
First row contains field names
체크
Source action
Process all files from source
[
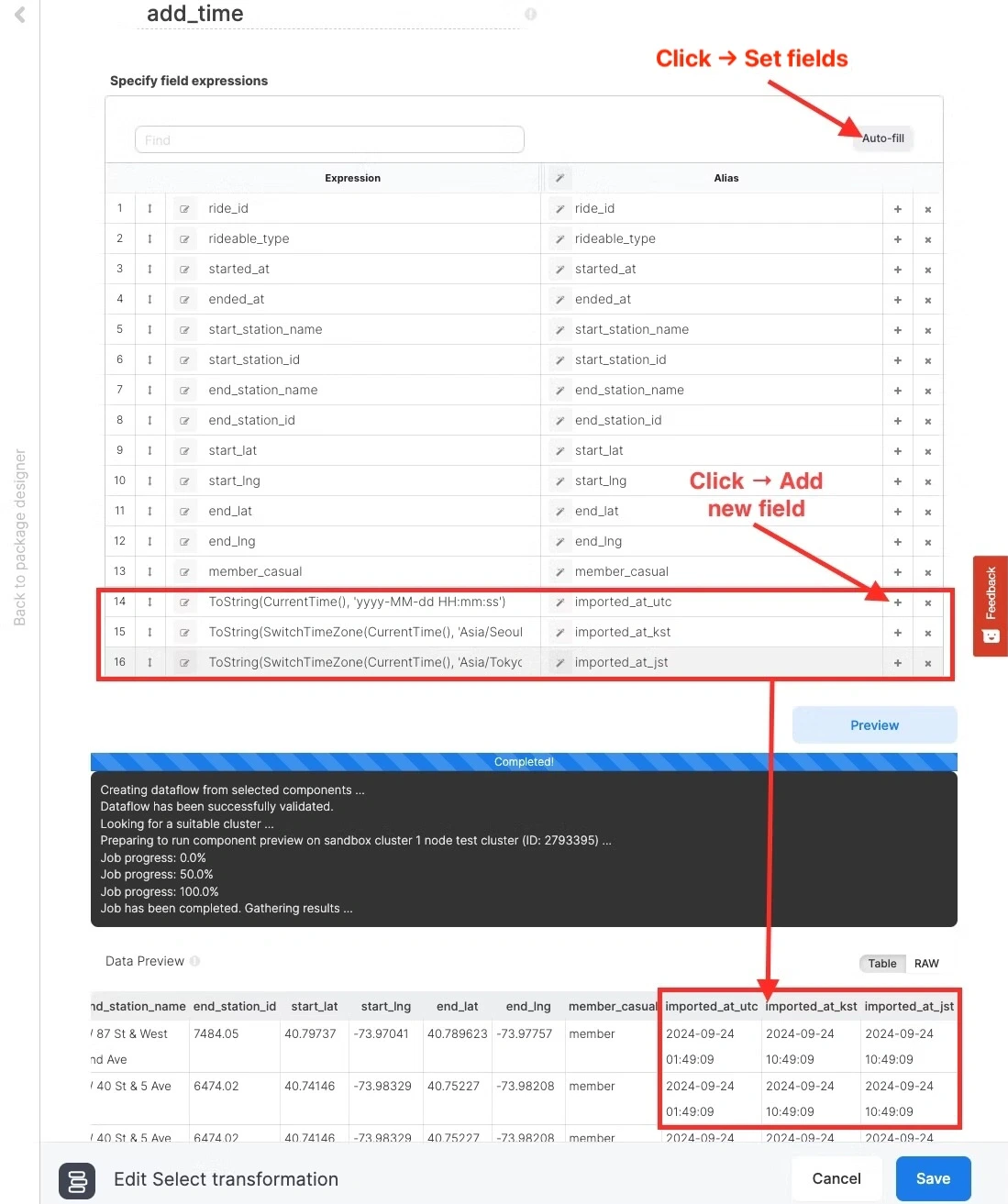
3. 세 가지 수집 날짜 및 시간대 추가
기존 데이터에 추가적으로 세 개의 타임존(UTC, KST, JST)으로 된 데이터 수집 일시 필드들을 추가합니다. 먼저 패키지 편집 화면에서 Select 컴포넌트를 추가하고 Auto-fill 버튼으로 소스의 필드들을 모두 추가해 둡니다. 그 다음 가장 마지막 필드로 이동하여 오른쪽의+를 클릭하면 새로운 필드가 추가되므로 아래 표에 따라 Alias와 Expression을 그대로 입력합니다. 확인을 위해 아래 그림과 같이 Previewボタンでデータを確認します。
Expression
Alias
ToString(CurrentTime(), 'yyyy-MM-dd HH:mm:ss')
imported_at_utc
ToString(SwitchTimeZone(CurrentTime(), 'Asia/Seoul'), 'yyyy-MM-dd HH:mm:ss')
imported_at_kst
ToString(SwitchTimeZone(CurrentTime(), 'Asia/Tokyo'), 'yyyy-MM-dd HH:mm:ss')
imported_at_jst
[
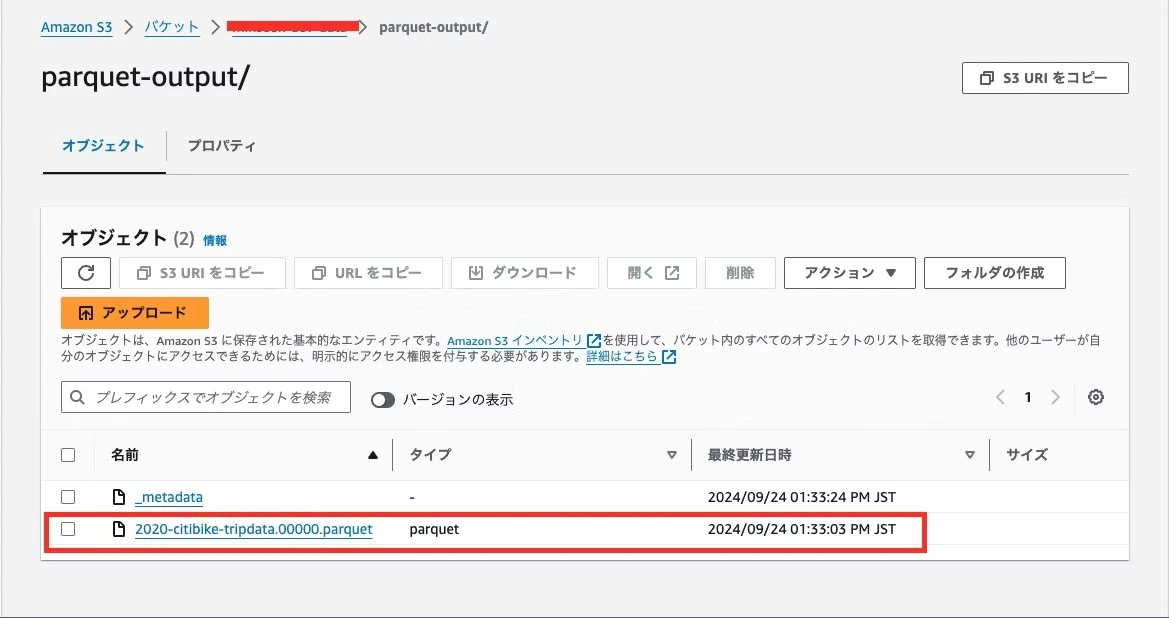
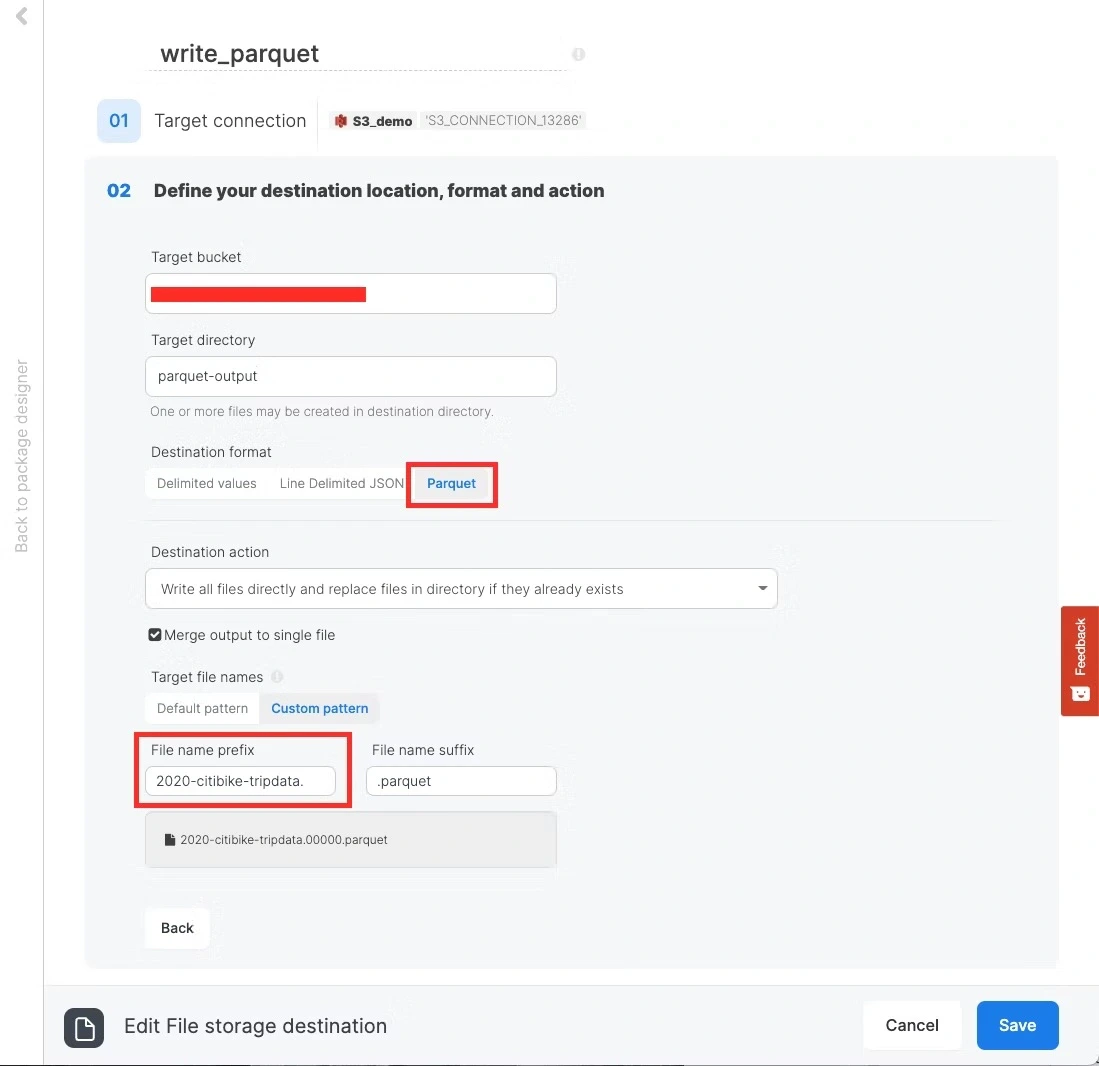
4. Parquet 형식으로 쓰기
데이터 수집 일시 필드들을 추가한 후, 정렬 컴포넌트에서 started_at 필드의 오름차순으로 데이터를 정렬합니다. 마지막으로 FileStorage destination을 연결하고 아래와 같이 세부 설정을 하면 패키지는 완성됩니다. 항목명 설정값 Connector S3 Target bucket 해당 커넥터의 버킷 이름 Target directoryparquet-output
Destination format
parquet
Merge output to single file
체크
Merge output to single file
Custom pattern
File name prefix
2020-citibike-tripdata.
[
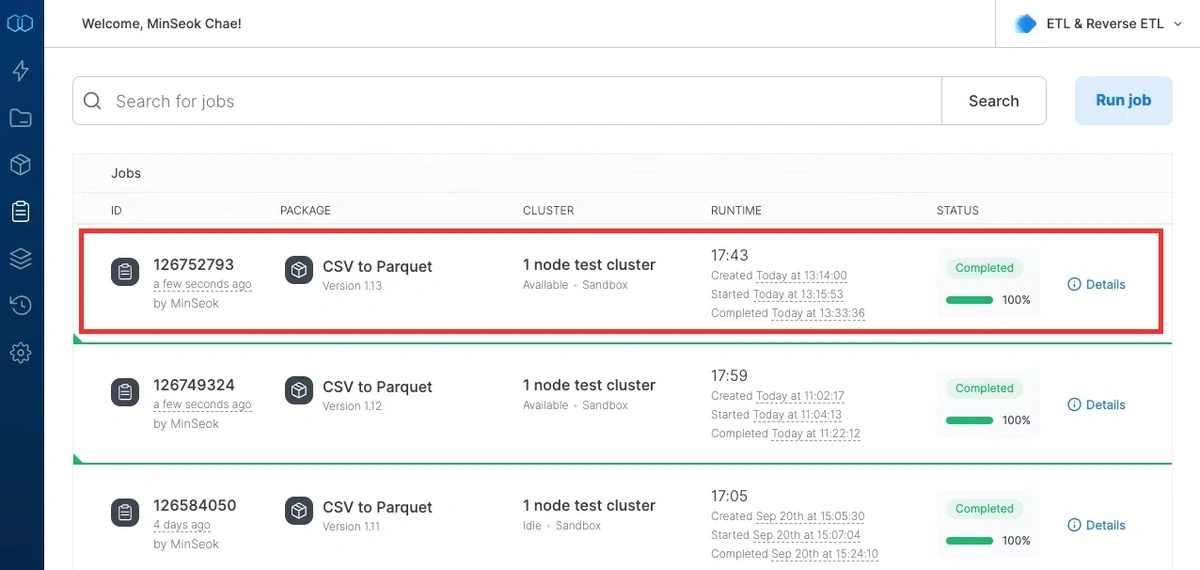
5. 패키지 실행 및 결과 확인
패키지를 실행하면 정렬을 한 경우에는 18분이 채 걸리지 않고, 정렬을 하지 않았을 경우 7분이 걸렸습니다. 아래 그림은 정렬을 한 경우의 결과를 보여주고 있습니다. [