

- 워크플로의 ‘File Mover’ 태스크로 파일 이동 및 삭제
File Mover 태스크란
Xplenty의 워크플로에는 File Mover 태스크가 탑재되어 있습니다. 이는 데이터 플로우 실행과는 독립적으로, 파일 스토리지 간에 파일 이동 및 복사를 수행하는 전용 태스크입니다. [
File Mover 태스크 설정 방법
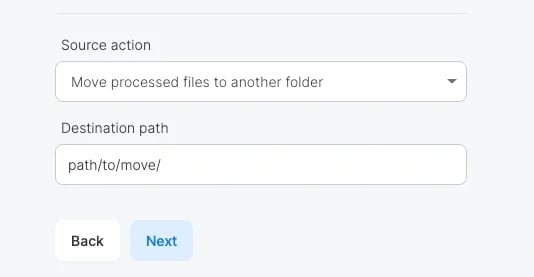
태스크 선택 화면에서 File Mover를 선택하고, 다음 항목을 설정합니다.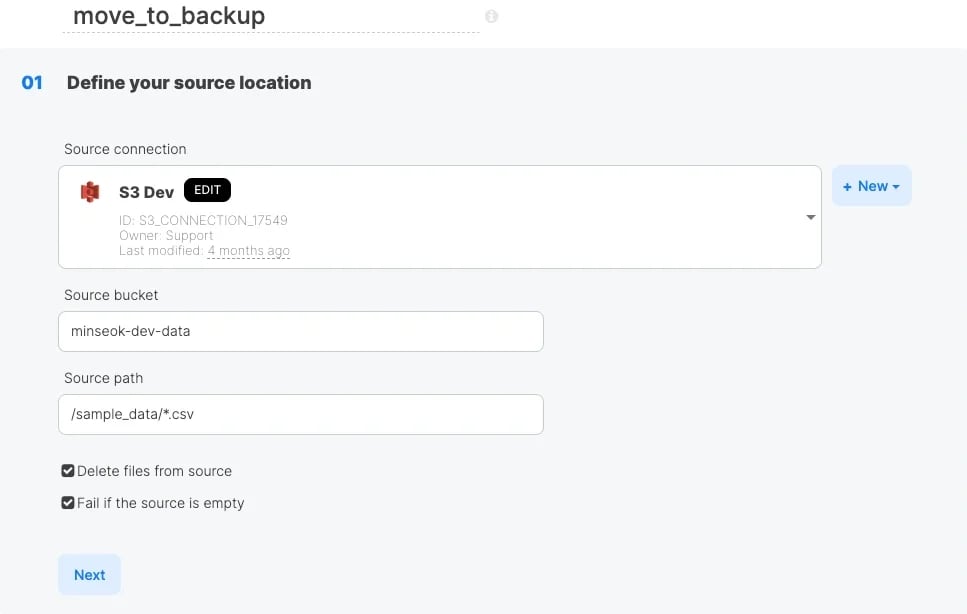
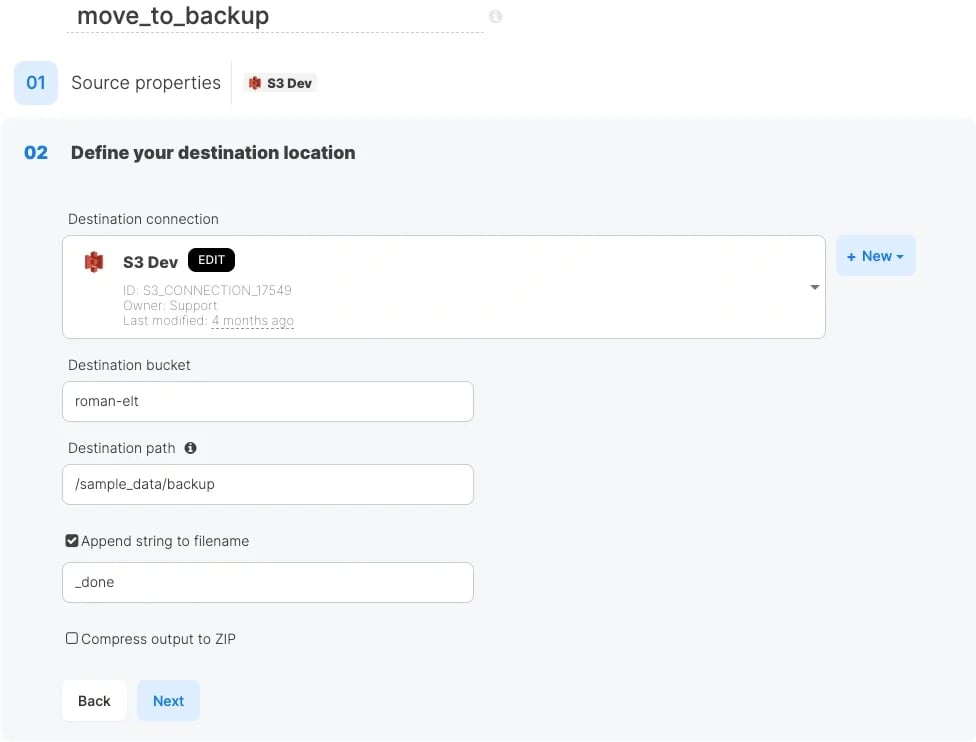
-
지정 문자열 :
_done - 파일 이름의 변경
-
이동전 :
menulist_20260317.csv -
이동후 :
menulist_20260317_done.csv
$변수명)나 와일드카드(*)도 사용할 수 있으므로, 날짜 변수를 활용한 동적인 아카이브 대상 지정 등도 구현할 수 있습니다.
전형적인 워크플로 구성 예시
[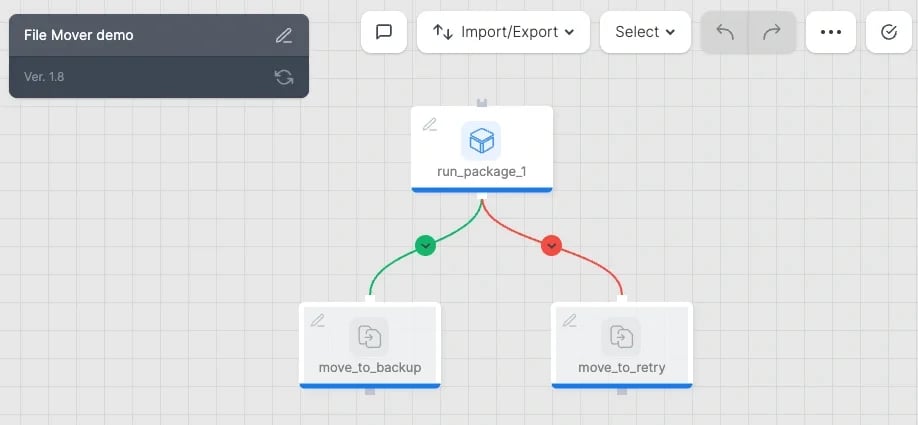
데이터 읽기와 동시에 조건 분기 성공·실패·완료 시 유연하게 제어 가능 없음 파일 삭제 ‘Delete files from source’로 대응 이동만 가능(삭제 미지원) 적합한 케이스 복잡한 파이프라인, 조건부 처리 간단한 단일 흐름 복잡한 처리 흐름이나 실패 시 처리가 필요한 경우에는 워크플로우의 File Mover 태스크가 적합합니다. 반면, 단순히 ‘읽으면 이동’으로 충분한 경우에는 File Storage Source 설정만으로 완료됩니다. 정리 Xplenty를 사용하면 데이터 전송 후의 파일 관리도 노코드로 자동화할 수 있습니다.