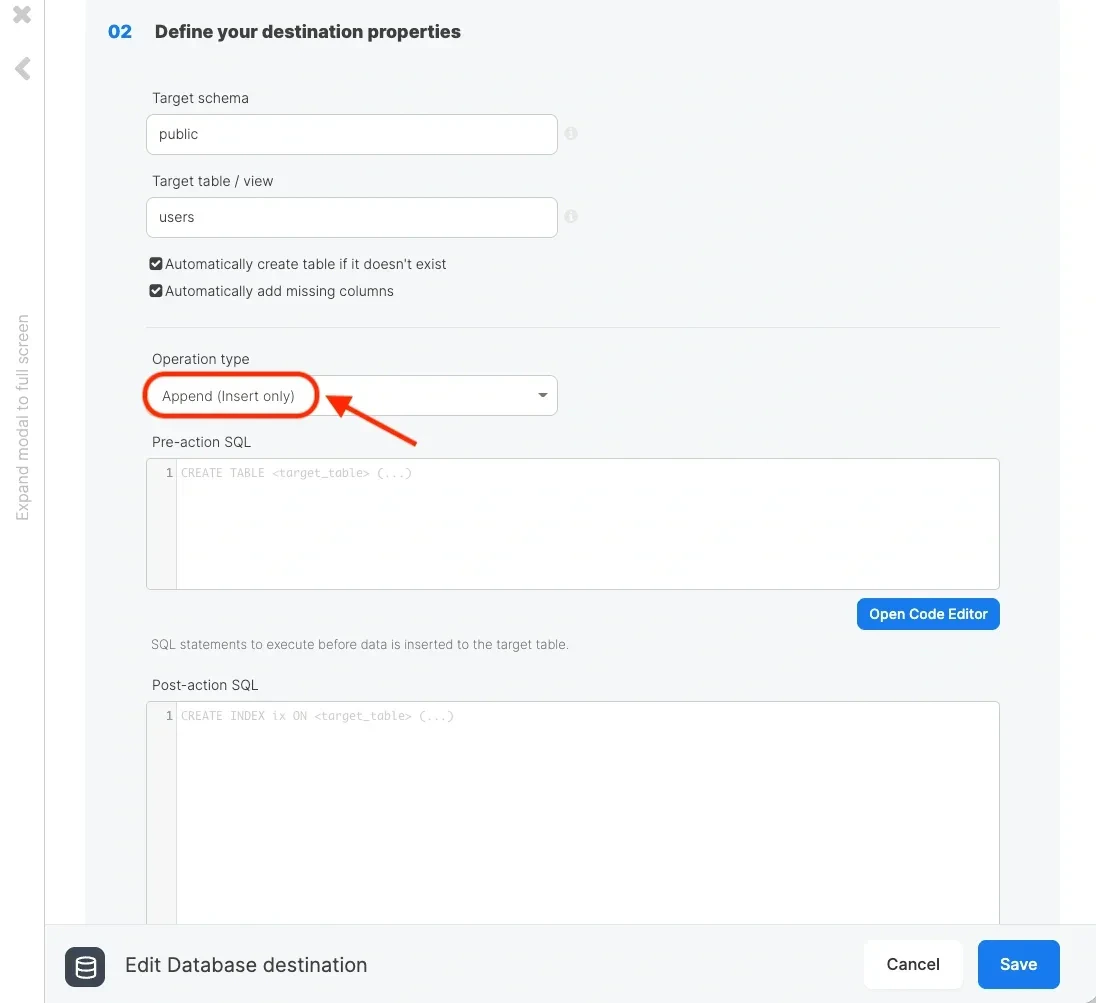
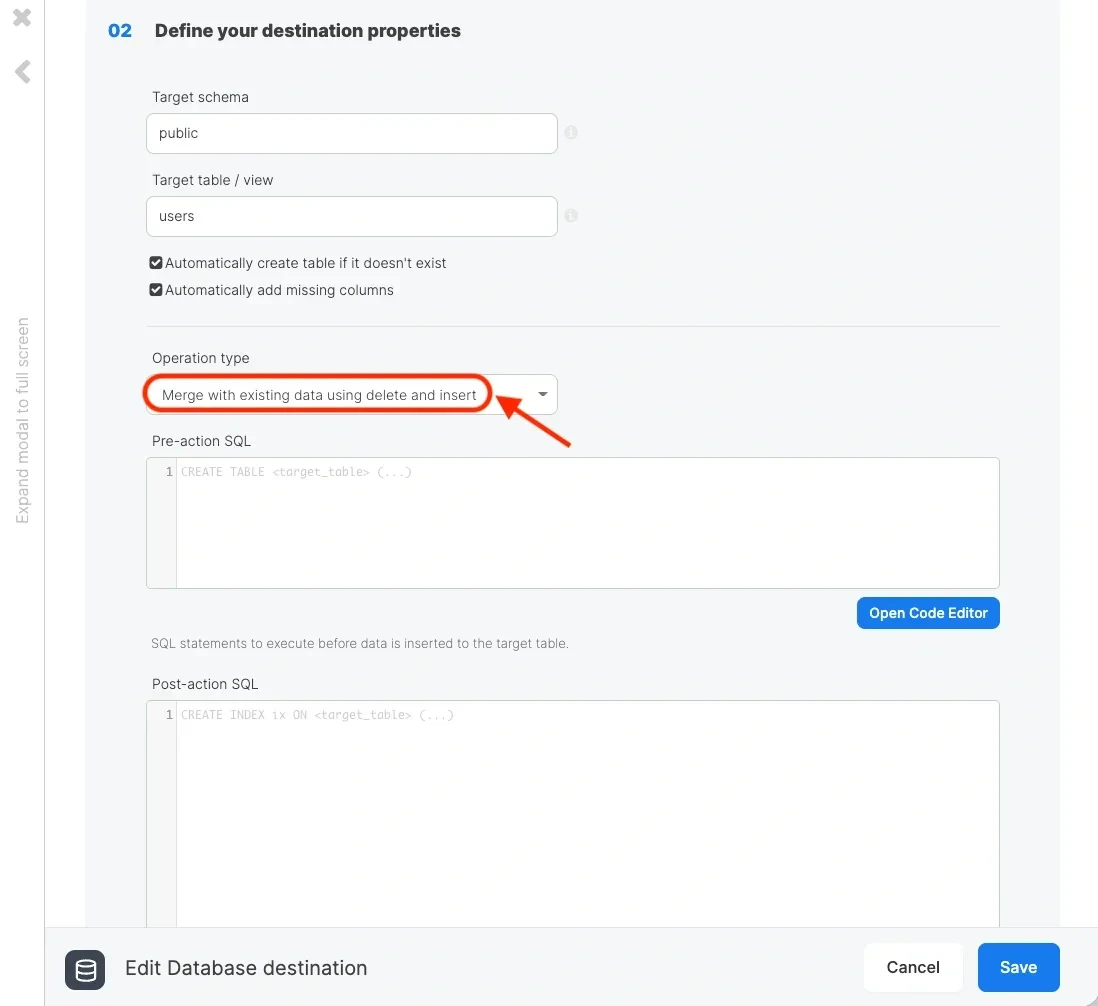
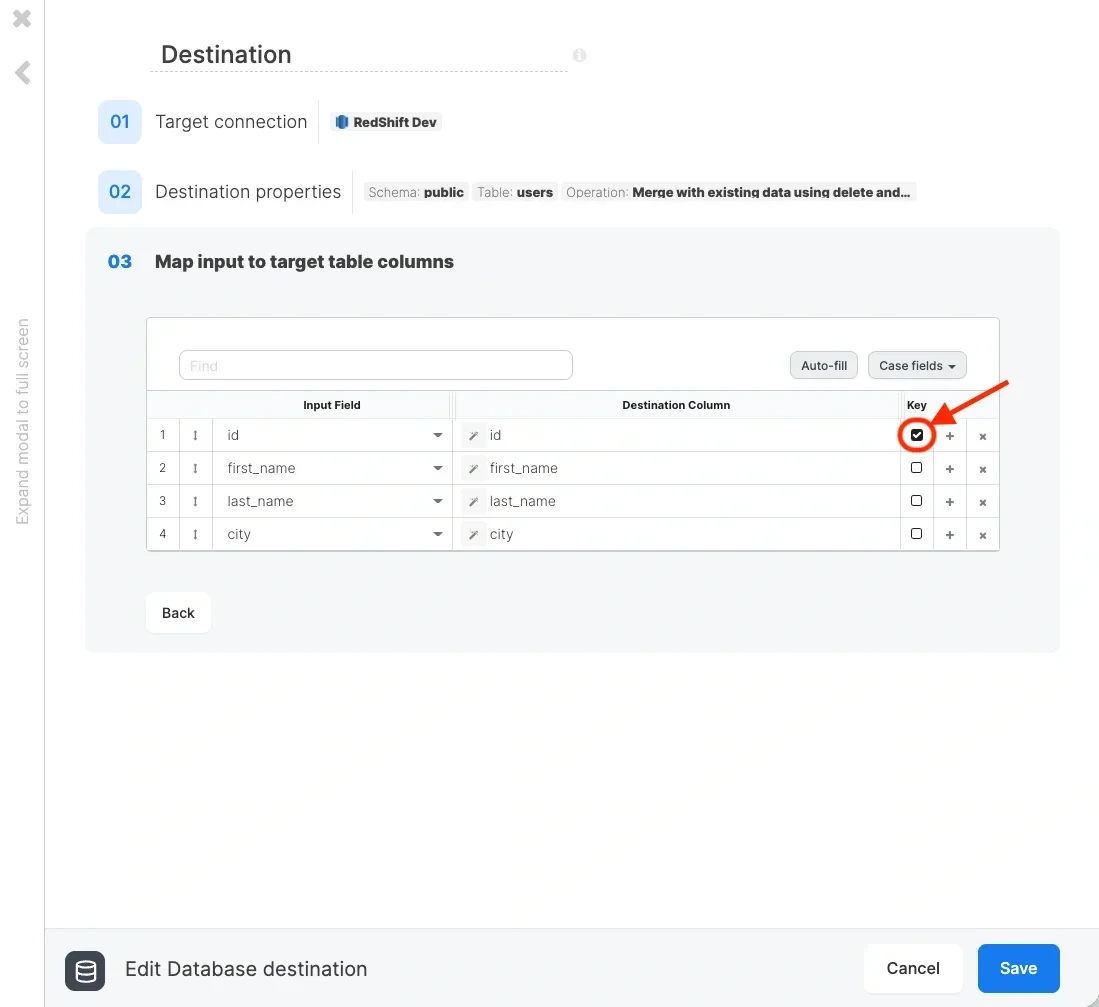
Reading increments from the source table
When using Integrate.io ETL to read data incrementally from the source, we need a timestamp column that specifies when the data was updated (or inserted in tables where data is only inserted). In our example, this column is called “updated_at”. When reading from the source table, we’ll use a where clause to only read the rows that were updated since the last time the package executed. It is highly recommended to index this column to improve the performance of the read query. For example, with PostgreSQL as the source, we can use the following where clause, in which $last_updated_at is a package variable and is placed within a string for casting to a PostgreSQL timestamp value: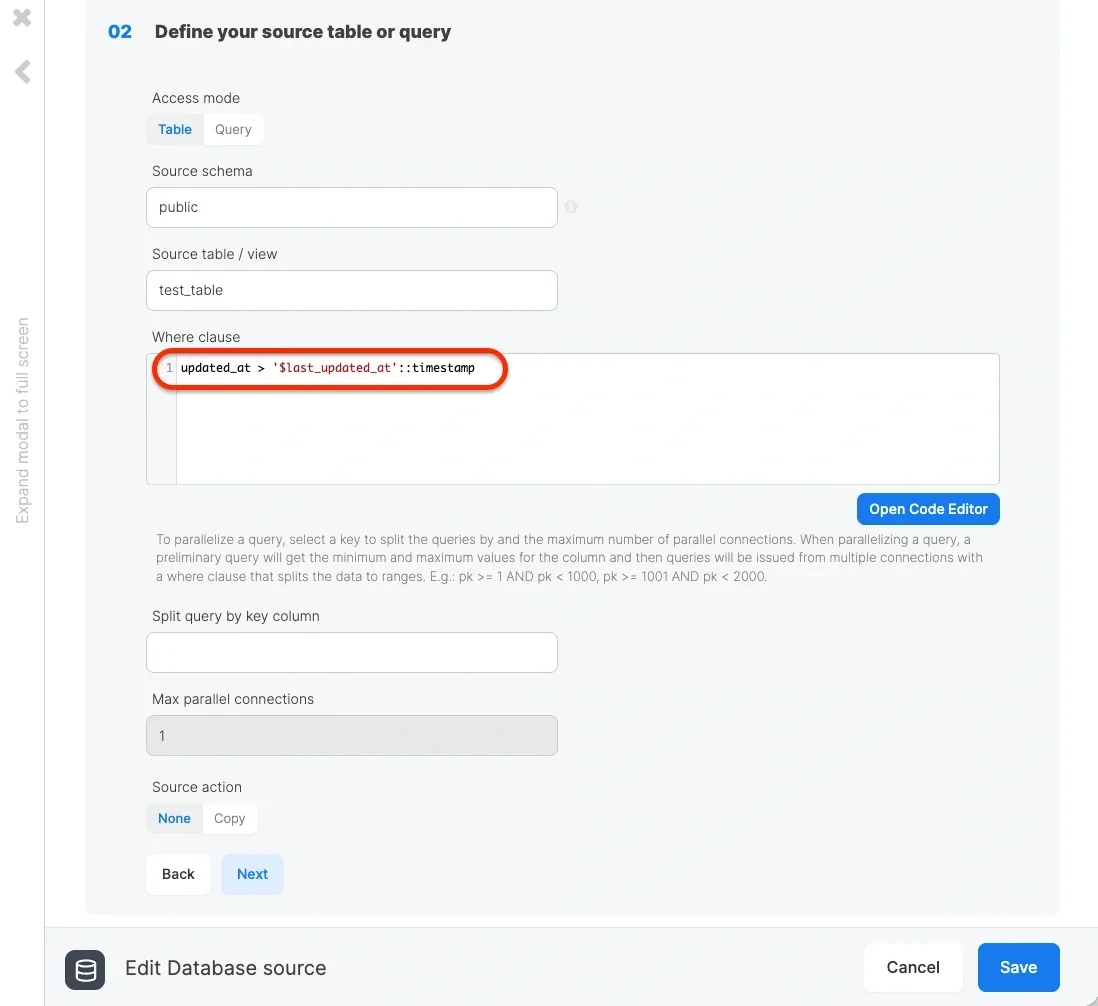
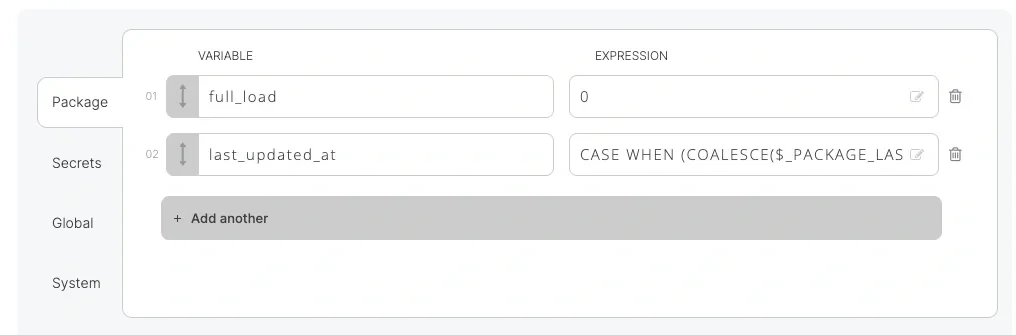
Note that the schema detection or data preview fails when using the variable in the where clause, as variables are not evaluated in design time. So what value (or rather evaluated expression) should we assign to the package variable? There are two options:
- Use the predefined variable _PACKAGE_LAST_SUCCESSFUL_JOB_SUBMISSION_TIMESTAMP which returns the submission timestamp for the last successful execution of the package. Wrap the variable with a CASE statement to handle empty values and to allow full load if required.
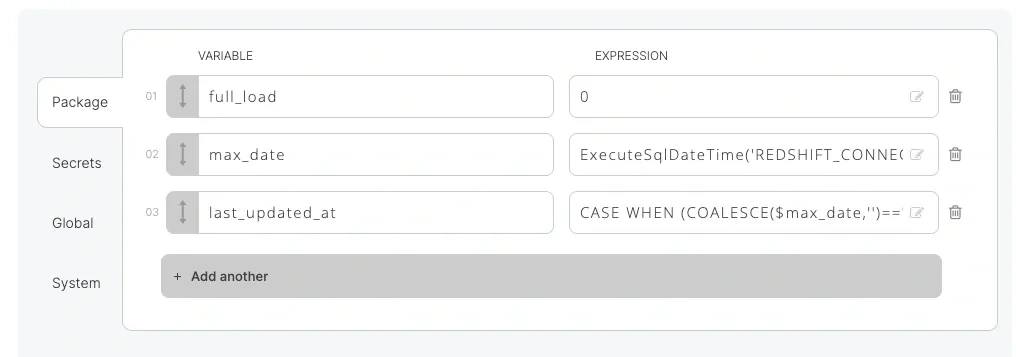
- Use the ExecuteSQL* functions (such as ExecuteSqlDateTime) to execute a query on the target database to get the max (last) value of updated_at in the target. This may be more accurate than the first option, but it requires an extra query on the destination.
Writing increments to the destination table
Writing increments to the destination (Redshift on any other relational database) is fairly straightforward. If the increments read from the source are for newly appended data only (no updates), you can simply append the data to the destination table.